
YARN 時間軸服務 v.2 是時間軸伺服器的下一個主要版本,繼 v.1 和 v.1.5 之後。V.2 的建立是為了解決 v.1 的兩個主要挑戰。
V.1 僅限於單一寫入器/讀取器和儲存個體,且無法擴充到小型叢集之外。V.2 使用更具可擴充性的分散式寫入器架構和可擴充性的後端儲存。
YARN 時間軸服務 v.2 將資料收集 (寫入) 與資料服務 (讀取) 分開。它使用分散式收集器,基本上每個 YARN 應用程式一個收集器。讀取器是獨立的個體,專門透過 REST API 提供查詢服務。
YARN 時間軸服務 v.2 選擇 Apache HBase 作為主要後端儲存,因為 Apache HBase 可擴充至大型規模,同時在讀取和寫入時維持良好的回應時間。
在許多情況下,使用者有興趣了解「流程」或 YARN 應用程式的邏輯群組層級的資訊。啟動一組或一系列 YARN 應用程式以完成一個邏輯應用程式更為常見。時間軸服務 v.2 明確支援流程的概念。此外,它支援在流程層級彙總指標。
此外,例如組態和指標等資訊會被視為一級公民並獲得支援。
下列圖表說明了建模流程的不同 YARN 實體之間的關係。
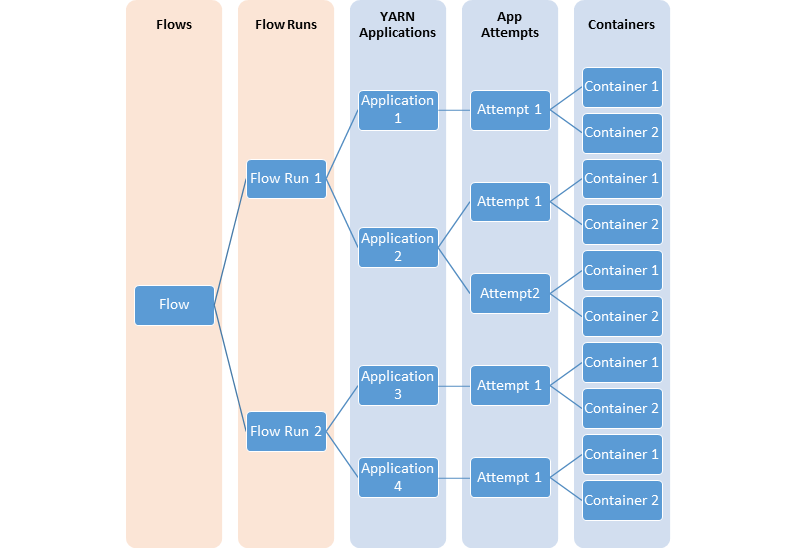
YARN 時間軸服務 v.2 使用一組收集器 (寫入器) 將資料寫入後端儲存。收集器會分散並與其專用的應用程式主控程式共同配置。屬於該應用程式的所有資料都會傳送至應用程式層級時間軸收集器,資源管理程式時間軸收集器除外。
對於特定應用程式,應用程式主控程式可以將應用程式資料寫入共同配置的時間軸收集器 (在此版本中為 NM 輔助服務)。此外,執行應用程式容器的其他節點的節點管理員也會將資料寫入執行應用程式主控程式的節點上的時間軸收集器。
資源管理程式也會維護自己的時間軸收集器。它只會發出 YARN 通用生命週期事件,以維持其寫入量合理。
時間軸讀取器是獨立於時間軸收集器的獨立守護程式,它們專門透過 REST API 提供查詢服務。
下列圖表說明了高層級設計。
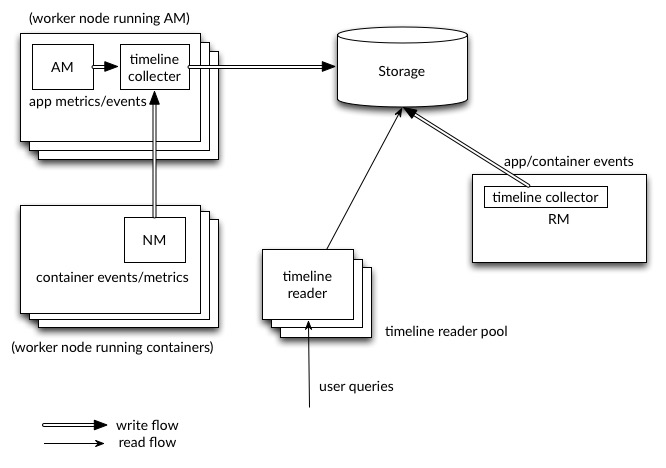
完整的端對端寫入和讀取流程已具備功能,並以 Apache HBase 作為後端。您應該可以開始產生資料。啟用後,所有 YARN 通用事件都會發布,以及 YARN 系統指標,例如 CPU 和記憶體。此外,包括 Distributed Shell 和 MapReduce 在內的一些應用程式可以將每個架構資料寫入 YARN Timeline Service v.2。
存取資料的基本模式是透過 REST。REST API 附帶許多有用且彈性的查詢模式(請參閱下方以取得更多資訊)。YARN Client 已與 ATSv2 整合。如果 ResouceManager 中沒有詳細資料,這會讓從 TimelineReader 擷取應用程式/嘗試/容器報告成為可能。
收集器(寫入器)目前嵌入在節點管理員中,作為輔助服務。資源管理員也有其專用的處理中收集器。讀取器目前是單一執行個體。目前無法在 YARN 應用程式的內容外寫入 Timeline Service(即沒有群集外客戶端)。
Kerberos 驗證已端對端支援。與 HBase 的所有通訊都可以進行 kerberization。請參閱 安全性設定 以取得組態。已經在可讀取時間軸資料的使用者和群組的可設定白名單方面,新增了對簡單授權的支援。預設允許群集管理員讀取時間軸資料。
當 YARN Timeline Service v.2 已停用時,可以預期對任何其他現有功能沒有功能或效能影響。
路線圖包括
v.2 引進的新設定參數標示為粗體。
| 設定屬性 | 說明 |
|---|---|
yarn.timeline-service.enabled |
指示客戶端時間軸服務是否已啟用。如果已啟用,應用程式使用的 TimelineClient 函式庫會將實體和事件張貼到時間軸伺服器。預設為 false。 |
yarn.timeline-service.version |
指示執行中時間軸服務的目前版本。例如,如果「yarn.timeline-service.version」為 1.5,且「yarn.timeline-service.enabled」為 true,表示群集將會且必須啟動時間軸服務 v.1.5(且沒有其他)。在客戶端方面,如果客戶端使用相同版本的時間軸服務,則必須成功。如果客戶端選擇使用較小版本,則結果會根據版本之間的相容性強固性而有所不同。預設為 1.0f。 |
yarn.timeline-service.writer.class |
後端儲存寫入器的類別。預設為 HBase 儲存寫入器。 |
yarn.timeline-service.reader.class |
後端儲存讀取器的類別。預設為 HBase 儲存讀取器。 |
yarn.system-metrics-publisher.enabled |
控制是否由 RM 和 NM 在時間軸服務上發佈 Yarn 系統指標的設定。預設為 false。 |
yarn.timeline-service.schema.prefix |
HBase 表格的架構前綴。預設為 “prod.”。 |
| 設定屬性 | 說明 |
|---|---|
yarn.timeline-service.hostname |
時間軸服務 Web 應用程式的主機名稱。預設為 0.0.0.0 |
yarn.timeline-service.reader.webapp.address |
時間軸讀取器 Web 應用程式的 http 位址。預設為 ${yarn.timeline-service.hostname}:8188。 |
yarn.timeline-service.reader.webapp.https.address |
時間軸讀取器 Web 應用程式的 https 位址。預設為 ${yarn.timeline-service.hostname}:8190。 |
yarn.timeline-service.reader.bind-host |
時間軸讀取器實際會繫結的位址。如果設定這個選用的位址,讀取器伺服器會繫結到這個位址和 yarn.timeline-service.reader.webapp.address 中指定的埠。這最常使用在透過設定為 0.0.0.0,讓服務監聽所有介面。 |
yarn.timeline-service.hbase.configuration.file |
選用的 hbase-site.xml 設定檔 URL,用於連線到時間軸服務的 HBase 群集。如果為空或未指定,HBase 設定會從類別路徑載入。如果指定,設定檔中指定的值會覆寫類別路徑中的值。預設為 null。 |
yarn.timeline-service.writer.flush-interval-seconds |
控制時間軸收集器沖刷時間軸寫入器的頻率的設定。預設為 60。 |
yarn.timeline-service.app-collector.linger-period.ms |
在應用程式主控端容器結束後,應用程式收集器在 NM 中保持運作的時間。預設為 60000 (60 秒)。 |
yarn.timeline-service.timeline-client.number-of-async-entities-to-merge |
時間軸 V2 客戶端嘗試合併這些數量非同步實體 (如果可用),然後呼叫 REST ATS V2 API 提交。預設為 10。 |
yarn.timeline-service.hbase.coprocessor.app-final-value-retention-milliseconds |
控制已完成應用程式的指標最終值在合併到流程總和之前保留多久的設定。預設為 259200000 (3 天)。這應該在 HBase 群集中設定。 |
yarn.rm.system-metrics-publisher.emit-container-events |
RM 控制是否將 Yarn 容器指標發佈至時間軸伺服器的設定。此組態設定適用於 ATS V2。預設為 false。 |
yarn.nodemanager.emit-container-events |
NM 控制是否將 Yarn 容器指標發佈至時間軸伺服器的設定。此組態設定適用於 ATS V2。預設為 true。 |
將 yarn.timeline-service.http-authentication.type 設定為 kerberos 可啟用安全性,之後可使用下列組態選項
| 設定屬性 | 說明 |
|---|---|
yarn.timeline-service.http-authentication.type |
定義時間軸伺服器 (收集器/讀取器) HTTP 端點所使用的驗證。支援的值:simple / kerberos / #AUTHENTICATION_HANDLER_CLASSNAME#。預設為 simple。 |
yarn.timeline-service.http-authentication.simple.anonymous.allowed |
表示使用「simple」驗證時,時間軸伺服器是否允許匿名要求。預設為 true。 |
yarn.timeline-service.http-authentication.kerberos.principal |
時間軸伺服器 (收集器/讀取器) HTTP 端點要使用的 Kerberos 主體。 |
yarn.timeline-service.http-authentication.kerberos.keytab |
時間軸伺服器 (收集器/讀取器) HTTP 端點要使用的 Kerberos 密鑰表。 |
yarn.timeline-service.principal |
時間軸讀取器的 Kerberos 主體。NM 主體會用於時間軸收集器,因為它在 NM 內部作為輔助服務執行。 |
yarn.timeline-service.keytab |
時間軸讀取器的 Kerberos 密鑰表。NM 密鑰表會用於時間軸收集器,因為它在 NM 內部作為輔助服務執行。 |
yarn.timeline-service.delegation.key.update-interval |
預設為 86400000 (1 天)。 |
yarn.timeline-service.delegation.token.renew-interval |
預設為 86400000 (1 天)。 |
yarn.timeline-service.delegation.token.max-lifetime |
預設為 604800000 (7 天)。 |
yarn.timeline-service.read.authentication.enabled |
啟用或停用時間軸服務 v2 資料的授權檢查。預設為 false,即停用。 |
yarn.timeline-service.read.allowed.users |
使用者清單,以逗號分隔,後接空格,然後是群組清單,以逗號分隔。它將允許此使用者和群組清單讀取資料,並拒絕其他人。預設值設定為 none。如果啟用授權,則此組態為強制性的。 |
yarn.webapp.filter-entity-list-by-user |
預設為 false。如果設定為 true,且 yarn.timeline-service.read.authentication.enabled 停用,則實體清單僅限於遠端使用者實體。它是 YARN 常見組態,用於列出 API。使用此組態,TimelineReader 會使用實體擁有者授權呼叫者 UGI。如果不符合,這些實體將從回應中移除。 |
如要為時間軸服務 v.2 啟用跨來源支援 (CORS),請設定下列組態參數
在 yarn-site.xml 中,將 yarn.timeline-service.http-cross-origin.enabled 設為 true。
在 core-site.xml 中,將 org.apache.hadoop.security.HttpCrossOriginFilterInitializer 加入 hadoop.http.filter.initializers。
如要取得更多用於跨來源支援的組態,請參閱 HttpAuthentication。請注意,如果 yarn.timeline-service.http-cross-origin.enabled 設為 true,會覆寫 hadoop.http.cross-origin.enabled。
準備時間軸服務 v.2 的儲存空間時,有幾個步驟需要執行
步驟 1) 設定 HBase 群集
步驟 2) 啟用協同處理器
步驟 3) 建立時間軸服務 v.2 的架構
以下會更詳細地說明每個步驟。
第一部分是設定或挑選一個 Apache HBase 群集作為儲存群集。支援的 Apache HBase 版本為 1.2.6 (預設) 和 2.0.0-beta1。1.0.x 版本無法與時間軸服務 v.2 搭配使用。預設情況下,Hadoop 發行版本會使用 HBase 1.2.6 建置。如要使用 HBase 2.0.0-beta1,請使用選項 -Dhbase.profile=2.0 從原始碼建置
HBase 有不同的部署模式。請參閱 HBase 手冊以了解這些模式,並挑選適合您設定的模式。(http://hbase.apache.org/book.html#standalone_dist)
如果您打算為 Apache HBase 群集設定簡單的部署設定檔,其中資料載入量較少,但資料需要在節點來來去去時持續存在,您可以考慮「獨立 HBase over HDFS」部署模式。
這是一個有用的獨立式 HBase 設定變體,所有 HBase 守護程式都在一個 JVM 內執行,但它並非持續存在於本機檔案系統,而是持續存在於 HDFS 實例中。寫入資料會複製到 HDFS,確保資料在節點來來去去時持續存在。若要設定這個獨立式變體,請編輯 hbase-site.xml,將 hbase.rootdir 設定為指向 HDFS 實例中的目錄,然後將 hbase.cluster.distributed 設定為 false。例如
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://namenode.example.org:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>false</value>
</property>
</configuration>
有關此模式的更多詳細資訊,請參閱 http://hbase.apache.org/book.html#standalone.over.hdfs 。
Apache HBase 群集準備好使用後,請執行下列步驟。
在此版本中,協同處理器是動態載入的(flowrun 表的表格協同處理器)。
將時序服務 jar 複製到 HBase 可以載入它的 HDFS。它在架構建立器中建立 flowrun 表時需要。預設 HDFS 位置為 /hbase/coprocessor。例如,
hadoop fs -mkdir /hbase/coprocessor
hadoop fs -put hadoop-yarn-server-timelineservice-hbase-coprocessor-3.2.0-SNAPSHOT.jar
/hbase/coprocessor/hadoop-yarn-server-timelineservice.jar
如果您想將 jar 放置在 hdfs 上的其他位置,還有一個稱為 yarn.timeline-service.hbase.coprocessor.jar.hdfs.location 的 yarn 設定。例如,
<property> <name>yarn.timeline-service.hbase.coprocessor.jar.hdfs.location</name> <value>/custom/hdfs/path/jarName</value> </property>
架構建立可以在將儲存時序服務表的 hbase 群集上執行。架構建立器工具需要 timelineservice-hbase 和 hbase-server jar。因此,在架構建立期間,您需要確保 hbase 類別路徑包含 yarn-timelineservice-hbase jar。
在 hbase 群集上,您可以從 hdfs 取得,因為我們在上述步驟中將它放在那裡供協同處理器使用。
hadoop fs -get /hbase/coprocessor/hadoop-yarn-server-timelineservice-hbase-client-${project.version}.jar <local-dir>/.
hadoop fs -get /hbase/coprocessor/hadoop-yarn-server-timelineservice-${project.version}.jar <local-dir>/.
hadoop fs -get /hbase/coprocessor/hadoop-yarn-server-timelineservice-hbase-common-${project.version}.jar <local-dir>/.
接下來,將它新增到 hbase 類別路徑,如下所示
export HBASE_CLASSPATH=$HBASE_CLASSPATH:/home/yarn/hadoop-current/share/hadoop/yarn/timelineservice/hadoop-yarn-server-timelineservice-hbase-client-${project.version}.jar
export HBASE_CLASSPATH=$HBASE_CLASSPATH:/home/yarn/hadoop-current/share/hadoop/yarn/timelineservice/hadoop-yarn-server-timelineservice-${project.version}.jar
export HBASE_CLASSPATH=$HBASE_CLASSPATH:/home/yarn/hadoop-current/share/hadoop/yarn/timelineservice/hadoop-yarn-server-timelineservice-hbase-common-${project.version}.jar
最後,執行架構建立器工具以建立必要的表格
bin/hbase org.apache.hadoop.yarn.server.timelineservice.storage.TimelineSchemaCreator -create
TimelineSchemaCreator 工具支援幾個選項,特別是在您進行測試時會很方便。例如,您可以使用 -skipExistingTable(簡稱 -s)來略過現有表格,並繼續建立其他表格,而不是讓架構建立失敗。預設情況下,表格的架構前綴為 “prod.”。當沒有提供選項或 ‘-help’(簡稱 ‘-h’)時,會印出命令用法。選項 (-entityTableName, -appToflowTableName, -applicationTableName, -subApplicationTableName) 將有助於覆寫預設表格名稱。在使用自訂表格名稱時,必須在 yarn.timeline-service.hbase.configuration.file 中設定的 hbase-site.xml 中設定以下對應的設定,其中包含自訂表格名稱。
yarn.timeline-service.app-flow.table.name yarn.timeline-service.entity.table.name yarn.timeline-service.application.table.name yarn.timeline-service.subapplication.table.name yarn.timeline-service.flowactivity.table.name yarn.timeline-service.flowrun.table.name yarn.timeline-service.domain.table.name
以下是啟動 Timeline 服務 v.2 的基本設定
<property> <name>yarn.timeline-service.version</name> <value>2.0f</value> </property> <property> <name>yarn.timeline-service.enabled</name> <value>true</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle,timeline_collector</value> </property> <property> <name>yarn.nodemanager.aux-services.timeline_collector.class</name> <value>org.apache.hadoop.yarn.server.timelineservice.collector.PerNodeTimelineCollectorsAuxService</value> </property> <property> <description>The setting that controls whether yarn system metrics is published on the Timeline service or not by RM And NM.</description> <name>yarn.system-metrics-publisher.enabled</name> <value>true</value> </property>
如果使用輔助服務清單,而不是透過設定檔設定輔助服務,請確保清單服務陣列包含 timeline_collector 服務,如下所示
{
"services": [
{
"name": "timeline_collector",
"configuration": {
"properties": {
"class.name": "org.apache.hadoop.yarn.server.timelineservice.collector.PerNodeTimelineCollectorsAuxService"
}
}
}
]
}
此外,如果您使用多個叢集將資料儲存在相同的 Apache HBase 儲存體中,您可能需要將 YARN 叢集名稱設定為合理的唯一值
<property> <name>yarn.resourcemanager.cluster-id</name> <value>my_research_test_cluster</value> </property>
另外,將 hbase-site.xml 設定檔新增至客戶端 Hadoop 叢集設定檔,以便它可以寫入您正在使用的 Apache HBase 叢集,或將 yarn.timeline-service.hbase.configuration.file 設定為指向 hbase-site.xml 的檔案 URL,例如
<property> <description> Optional URL to an hbase-site.xml configuration file to be used to connect to the timeline-service hbase cluster. If empty or not specified, then the HBase configuration will be loaded from the classpath. When specified the values in the specified configuration file will override those from the ones that are present on the classpath. </description> <name>yarn.timeline-service.hbase.configuration.file</name> <value>file:/etc/hbase/hbase-ats-dc1/hbase-site.xml</value> </property>
若要設定 Timeline 服務 1.5 和 v.2,請新增下列屬性
<property> <name>yarn.timeline-service.versions</name> <value>1.5f,2.0f</value> </property>
如果未設定上述內容,則預設為 yarn.timeline-service.version 中設定的版本
重新啟動資源管理員和節點管理員,以選取新的設定檔。收集器會以嵌入方式在資源管理員和節點管理員中啟動。
Timeline 服務讀取器是獨立的 YARN 守護程式,可以使用下列語法啟動
$ yarn-daemon.sh start timelinereader
若要將 MapReduce 架構資料寫入 Timeline 服務 v.2,請在 mapred-site.xml 中啟用下列設定檔
<property> <name>mapreduce.job.emit-timeline-data</name> <value>true</value> </property>
如果您目前執行的是 Timeline 服務 v2 alpha1 版本,我們建議您執行下列動作
清除表格中的現有資料(截斷表格),因為 AppToFlow 的列關鍵字已變更。
協同處理器現在是 GA 中動態載入的表格層級協同處理器。我們建議刪除表格、將 hdfs 上的協同處理器 jar 替換為 GA,重新啟動區域伺服器,並重新建立 flowrun 表格。
此部分適用於想要與 Timeline 服務 v.2 整合的 YARN 應用程式開發人員。
開發人員需要使用 TimelineV2Client API 來將每個架構的資料發佈到時間軸服務 v.2。v.2 的實體/物件 API 與 v.1 不同,因為物件模型已大幅變更。v.2 時間軸實體類別為 org.apache.hadoop.yarn.api.records.timelineservice.TimelineEntity。
時間軸服務 v.2 putEntities 方法有 2 種:putEntities 和 putEntitiesAsync。前者是一個封鎖操作,必須用來寫入更重要的資料(例如生命週期事件)。後者是一個非封鎖操作。請注意,兩者都沒有傳回值。
建立 TimelineV2Client 包括將應用程式 ID 傳遞到靜態方法 TimelineV2Client.createTimelineClient。
例如
// Create and start the Timeline client v.2
TimelineV2Client timelineClient =
TimelineV2Client.createTimelineClient(appId);
timelineClient.init(conf);
timelineClient.start();
try {
TimelineEntity myEntity = new TimelineEntity();
myEntity.setType("MY_APPLICATION");
myEntity.setId("MyApp1");
// Compose other entity info
// Blocking write
timelineClient.putEntities(myEntity);
TimelineEntity myEntity2 = new TimelineEntity();
// Compose other info
// Non-blocking write
timelineClient.putEntitiesAsync(myEntity2);
} catch (IOException | YarnException e) {
// Handle the exception
} finally {
// Stop the Timeline client
timelineClient.stop();
}
如上所示,您需要指定 YARN 應用程式 ID 才能寫入時間軸服務 v.2。請注意,目前您需要在叢集上才能寫入時間軸服務。例如,應用程式主控程式或容器中的程式碼可以寫入時間軸服務,而叢集外 MapReduce 工作提交程式則不行。
在建立時間軸 v2 應用程式後,使用者還需要設定時間軸收集器資訊,其中包含收集器地址和收集器權杖(僅限於安全模式)。如果使用 AMRMClient,則透過呼叫 AMRMClient#registerTimelineV2Client 來註冊時間軸應用程式就足夠了。
amRMClient.registerTimelineV2Client(timelineClient);
否則,需要從 AM 分配回應中擷取地址,並明確設定在時間軸應用程式中。
timelineClient.setTimelineCollectorInfo(response.getCollectorInfo());
您可以建立並發佈自己的實體、事件和指標,就像之前的版本一樣。
TimelineEntity 物件有下列欄位來儲存時間軸資料
請注意,在張貼時間軸指標時,可以透過 TimelineMetric#setRealtimeAggregationOp() 方法選擇要如何彙總每個指標。這裡的「彙總」表示對一組實體套用其中一個 TimelineMetricOperation。時間軸服務 v2 提供內建應用程式層級彙總,表示彙總同一個 YARN 應用程式中不同時間軸實體的指標。目前,TimelineMetricOperation 中支援兩種運算:
MAX:取得所有 TimelineMetric 物件中的最大值。SUM:取得所有 TimelineMetric 物件的總和。預設情況下,NOP 運算表示不執行任何即時彙總運算。
應用程式架構必須盡可能設定「流程內容」,才能利用時間軸服務 v.2 提供的流程支援。流程內容包含以下項目:
如果未指定流程內容,會為這些屬性提供預設值:
您可以透過 YARN 應用程式標籤提供流程內容
ApplicationSubmissionContext appContext = app.getApplicationSubmissionContext();
// set the flow context as YARN application tags
Set<String> tags = new HashSet<>();
tags.add(TimelineUtils.generateFlowNameTag("distributed grep"));
tags.add(Timelineutils.generateFlowVersionTag("3df8b0d6100530080d2e0decf9e528e57c42a90a"));
tags.add(TimelineUtils.generateFlowRunIdTag(System.currentTimeMillis()));
appContext.setApplicationTags(tags);
注意:資源管理員會在儲存 YARN 應用程式標籤之前將其轉換為小寫。因此,在 REST API 查詢中使用流程名稱和流程版本之前,應將其轉換為小寫。
目前僅透過 REST API 支援查詢時間軸服務 v.2;YARN 函式庫中未實作 API 程式碼。
v.2 REST API 在時間軸服務網路服務上實作於路徑 /ws/v2/timeline/ 下。
以下是 API 的非正式說明。
GET /ws/v2/timeline/
傳回描述服務執行個體和版本資訊的 JSON 物件。
{
"About":"Timeline Reader API",
"timeline-service-version":"3.0.0-alpha1-SNAPSHOT",
"timeline-service-build-version":"3.0.0-alpha1-SNAPSHOT from fb0acd08e6f0b030d82eeb7cbfa5404376313e60 by sjlee source checksum be6cba0e42417d53be16459e1685e7",
"timeline-service-version-built-on":"2016-04-11T23:15Z",
"hadoop-version":"3.0.0-alpha1-SNAPSHOT",
"hadoop-build-version":"3.0.0-alpha1-SNAPSHOT from fb0acd08e6f0b030d82eeb7cbfa5404376313e60 by sjlee source checksum ee968fd0aedcc7384230ee3ca216e790",
"hadoop-version-built-on":"2016-04-11T23:14Z"
}
以下顯示 REST API 上支援的查詢。
使用「查詢流程」API,您可以擷取最近執行過的活躍流程清單。如果使用不含叢集名稱的 REST 端點,則會採用 `yarn-site.xml` 中設定 `yarn.resourcemanager.cluster-id` 所指定的叢集。如果沒有任何流程符合謂詞,則會傳回一個空清單。
GET /ws/v2/timeline/clusters/{cluster name}/flows/
or
GET /ws/v2/timeline/flows/
limit - 如果指定,則定義要傳回的流程數目。`limit` 的最大可能值是 Long 的最大值。如果未指定或值小於 0,則會將 `limit` 視為 100。daterange - 如果指定,則以「[開始日期]-[結束日期]」(即以「-」分隔的開始日期和結束日期) 或單一日期提供。日期以 yyyyMMdd 格式詮釋,並假設為 UTC。如果指定單一日期,則會傳回在該日期活躍的所有流程。如果同時提供開始日期和結束日期,則會傳回在開始日期和結束日期之間活躍的所有流程。如果只提供開始日期,則會傳回在開始日期當天或之後活躍的流程。如果只提供結束日期,則會傳回在結束日期當天或之前活躍的流程。fromid - 如果指定,則會從指定的 `fromid` 擷取下一組流程。擷取的實體組包含指定的 `fromid`。`fromid` 應取自先前傳送的流程實體回應中與 FROM_ID 資訊金鑰關聯的值。[
{
"metrics": [],
"events": [],
"id": "test-cluster/1460419200000/sjlee@ds-date",
"type": "YARN_FLOW_ACTIVITY",
"createdtime": 0,
"flowruns": [
{
"metrics": [],
"events": [],
"id": "sjlee@ds-date/1460420305659",
"type": "YARN_FLOW_RUN",
"createdtime": 0,
"info": {
"SYSTEM_INFO_FLOW_VERSION": "1",
"SYSTEM_INFO_FLOW_RUN_ID": 1460420305659,
"SYSTEM_INFO_FLOW_NAME": "ds-date",
"SYSTEM_INFO_USER": "sjlee"
},
"isrelatedto": {},
"relatesto": {}
},
{
"metrics": [],
"events": [],
"id": "sjlee@ds-date/1460420587974",
"type": "YARN_FLOW_RUN",
"createdtime": 0,
"info": {
"SYSTEM_INFO_FLOW_VERSION": "1",
"SYSTEM_INFO_FLOW_RUN_ID": 1460420587974,
"SYSTEM_INFO_FLOW_NAME": "ds-date",
"SYSTEM_INFO_USER": "sjlee"
},
"isrelatedto": {},
"relatesto": {}
}
],
"info": {
"SYSTEM_INFO_CLUSTER": "test-cluster",
"UID": "test-cluster!sjlee!ds-date",
"FROM_ID": "test-cluster!1460419200000!sjlee!ds-date",
"SYSTEM_INFO_FLOW_NAME": "ds-date",
"SYSTEM_INFO_DATE": 1460419200000,
"SYSTEM_INFO_USER": "sjlee"
},
"isrelatedto": {},
"relatesto": {}
}
]
透過 Query Flow Runs API,您可以進一步深入了解特定流程的執行(特定執行個體)。這會傳回屬於給定流程的最新執行。如果使用沒有群集名稱的 REST 端點,則會採用在 yarn-site.xml 中的 yarn.resourcemanager.cluster-id 設定所指定的群集。如果沒有任何流程執行符合謂詞,則會傳回一個空清單。
GET /ws/v2/timeline/clusters/{cluster name}/users/{user name}/flows/{flow name}/runs/
or
GET /ws/v2/timeline/users/{user name}/flows/{flow name}/runs/
limit - 如果指定,則定義要傳回的流程數目。`limit` 的最大可能值是 Long 的最大值。如果未指定或值小於 0,則會將 `limit` 視為 100。createdtimestart - 如果有指定,則只會傳回在此時間戳記之後開始的流程執行。createdtimeend - 如果有指定,則只會傳回在此時間戳記之前開始的流程執行。metricstoretrieve - 如果有指定,則會定義要擷取哪些指標,或是不擷取哪些指標並在回應中傳回。metricstoretrieve 可以是下列形式的運算式:METRICS,都會擷取指標。請注意,網址不安全的字元(例如空格)必須適當地編碼。fields - 指定要擷取哪些欄位。對於查詢流程執行,只有 ALL 或 METRICS 是有效的欄位。其他欄位會導致 HTTP 400(錯誤的請求)回應。如果沒有指定,則會在回應中傳回 id、type、createdtime 和 info 欄位。fromid - 如果有指定,則會從給定的 fromid 擷取下一組流程執行實體。擷取的實體組包含指定的 fromid。fromid 應從先前傳送的流程實體回應中與 FROM_ID info 鍵關聯的值取得。[
{
"metrics": [],
"events": [],
"id": "sjlee@ds-date/1460420587974",
"type": "YARN_FLOW_RUN",
"createdtime": 1460420587974,
"info": {
"UID": "test-cluster!sjlee!ds-date!1460420587974",
"FROM_ID": "test-cluster!sjlee!ds-date!1460420587974",
"SYSTEM_INFO_FLOW_RUN_ID": 1460420587974,
"SYSTEM_INFO_FLOW_NAME": "ds-date",
"SYSTEM_INFO_FLOW_RUN_END_TIME": 1460420595198,
"SYSTEM_INFO_USER": "sjlee"
},
"isrelatedto": {},
"relatesto": {}
},
{
"metrics": [],
"events": [],
"id": "sjlee@ds-date/1460420305659",
"type": "YARN_FLOW_RUN",
"createdtime": 1460420305659,
"info": {
"UID": "test-cluster!sjlee!ds-date!1460420305659",
"FROM_ID": "test-cluster!sjlee!ds-date!1460420305659",
"SYSTEM_INFO_FLOW_RUN_ID": 1460420305659,
"SYSTEM_INFO_FLOW_NAME": "ds-date",
"SYSTEM_INFO_FLOW_RUN_END_TIME": 1460420311966,
"SYSTEM_INFO_USER": "sjlee"
},
"isrelatedto": {},
"relatesto": {}
}
]
使用此 API,您可以查詢由叢集、使用者、流程名稱和執行 ID 識別的特定流程執行。如果使用沒有叢集名稱的 REST 端點,則會採用在 yarn-site.xml 中的設定 yarn.resourcemanager.cluster-id 所指定的叢集。查詢個別流程執行時,預設會傳回指標。
GET /ws/v2/timeline/clusters/{cluster name}/users/{user name}/flows/{flow name}/runs/{run id}
or
GET /ws/v2/timeline/users/{user name}/flows/{flow name}/runs/{run id}
metricstoretrieve - 如果有指定,則會定義要擷取哪些指標,或是不擷取哪些指標並在回應中傳回。metricstoretrieve 可以是下列形式的運算式:{
"metrics": [
{
"type": "SINGLE_VALUE",
"id": "org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter:BYTES_READ",
"aggregationOp": "NOP",
"values": {
"1465246377261": 118
}
},
{
"type": "SINGLE_VALUE",
"id": "org.apache.hadoop.mapreduce.lib.output.FileOutputFormatCounter:BYTES_WRITTEN",
"aggregationOp": "NOP",
"values": {
"1465246377261": 97
}
}
],
"events": [],
"id": "varun@QuasiMonteCarlo/1465246348599",
"type": "YARN_FLOW_RUN",
"createdtime": 1465246348599,
"isrelatedto": {},
"info": {
"UID":"yarn-cluster!varun!QuasiMonteCarlo!1465246348599",
"FROM_ID":"yarn-cluster!varun!QuasiMonteCarlo!1465246348599",
"SYSTEM_INFO_FLOW_RUN_END_TIME":1465246378051,
"SYSTEM_INFO_FLOW_NAME":"QuasiMonteCarlo",
"SYSTEM_INFO_USER":"varun",
"SYSTEM_INFO_FLOW_RUN_ID":1465246348599
},
"relatesto": {}
}
使用此 API,您可以查詢屬於特定流程的所有 YARN 應用程式。如果使用沒有叢集名稱的 REST 端點,則會採用在 yarn-site.xml 中的設定 yarn.resourcemanager.cluster-id 所指定的叢集。如果符合條件的應用程式數量超過限制,則會傳回符合條件的最新應用程式,數量最多為限制值。如果沒有任何應用程式符合條件,則會傳回空清單。
GET /ws/v2/timeline/clusters/{cluster name}/users/{user name}/flows/{flow name}/apps
or
GET /ws/v2/timeline/users/{user name}/flows/{flow name}/apps
limit - 如果指定,則定義要傳回的應用程式數量。limit 的最大可能值是 Long 的最大值。如果未指定或值小於 0,則會將 limit 視為 100。createdtimestart - 如果指定,則只會傳回在此時間戳記之後建立的應用程式。createdtimeend - 如果指定,則只會傳回在此時間戳記之前建立的應用程式。relatesto - 如果指定,則符合條件的應用程式必須與與實體類型相關聯的給定實體相關或不相關。relatesto 表示為下列形式的表達式:isrelatedto - 如果指定,則符合條件的應用程式必須與與實體類型關聯的特定實體相關或不相關。isrelatedto 的表示方式與 relatesto 相同。infofilters - 如果指定,則符合條件的應用程式必須與特定資訊金鑰完全符合,且必須等於或不等於特定值。資訊金鑰是字串,但值可以是任何物件。infofilters 的表示方式為下列形式的表達式:conffilters - 如果指定,則符合條件的應用程式必須與特定設定名稱完全符合,且必須等於或不等於特定設定值。設定名稱和值都必須是字串。conffilters 的表示方式與 infofilters 相同。metricfilters - 如果指定,則符合條件的應用程式必須與特定指標完全符合,並滿足與指標值指定的關係。指標 ID 必須是字串,指標值必須是整數值。metricfilters 的表示方式為下列形式的表達式:事件篩選器 - 如果有指定,配對的應用程式必須包含或不包含特定事件,視表達式而定。事件篩選器表示為以下形式的表達式:metricstoretrieve - 如果有指定,則會定義要擷取哪些指標,或是不擷取哪些指標並在回應中傳回。metricstoretrieve 可以是下列形式的運算式:METRICS,都會擷取指標。請注意,網址不安全的字元(例如空格)必須適當地編碼。要擷取的組態 - 如果有指定,會定義要擷取或不擷取哪些組態,並在回應中傳送回來。要擷取的組態可以是以下形式的表達式:CONFIGS,都將擷取設定檔。請注意,URL 不安全的字元(例如空格)必須適當地編碼。fields - 指定要擷取哪些欄位。fields 的可能值可以是 EVENTS、INFO、CONFIGS、METRICS、RELATES_TO、IS_RELATED_TO 和 ALL。如果指定 ALL,將會擷取所有欄位。可以使用逗號分隔清單指定多個欄位。如果未指定 fields,則回應中將傳回 app id、類型(等同於 YARN_APPLICATION)、app 建立時間和 info 欄位中的 UID。metricslimit - 如果指定,則定義要傳回的指標數量。僅在 fields 包含 METRICS/ALL 或指定 metricstoretrieve 時考量。否則會忽略。metricslimit 的最大可能值可以是 Integer 的最大值。如果未指定或值小於 1,且必須擷取指標,則 metricslimit 將視為 1,亦即傳回指標的最新單一值。metricstimestart - 如果指定,則傳回此時間戳記之後的實體指標。metricstimeend - 如果指定,則傳回此時間戳記之前的實體指標。fromid - 如果指定,則從指定的 fromid 擷取下一組應用程式實體。擷取的實體組包含指定的 fromid。fromid 應從稍早傳送的流程實體回應中與 FROM_ID 資訊金鑰關聯的值取得。[
{
"metrics": [ ],
"events": [ ],
"type": "YARN_APPLICATION",
"id": "application_1465246237936_0001",
"createdtime": 1465246348599,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!application_1465246237936_0001"
"FROM_ID": "yarn-cluster!varun!QuasiMonteCarlo!1465246348599!application_1465246237936_0001",
},
"relatesto": { }
},
{
"metrics": [ ],
"events": [ ],
"type": "YARN_APPLICATION",
"id": "application_1464983628730_0005",
"createdtime": 1465033881959,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!application_1464983628730_0005"
"FROM_ID": "yarn-cluster!varun!QuasiMonteCarlo!1465246348599!application_1464983628730_0005",
},
"relatesto": { }
}
]
使用此 API,您可以查詢屬於特定流程執行的所有 YARN 應用程式。如果使用不含叢集名稱的 REST 端點,則會採用 yarn-site.xml 中 yarn.resourcemanager.cluster-id 設定檔指定的叢集。如果符合條件的應用程式數量超過限制,則將傳回最多最近的應用程式(至限制為止)。如果沒有任何應用程式符合謂詞,則會傳回空清單。
GET /ws/v2/timeline/clusters/{cluster name}/users/{user name}/flows/{flow name}/runs/{run id}/apps
or
GET /ws/v2/timeline/users/{user name}/flows/{flow name}/runs/{run id}/apps/
limit - 如果指定,則定義要傳回的應用程式數量。limit 的最大可能值是 Long 的最大值。如果未指定或值小於 0,則會將 limit 視為 100。createdtimestart - 如果指定,則只會傳回在此時間戳記之後建立的應用程式。createdtimeend - 如果指定,則只會傳回在此時間戳記之前建立的應用程式。relatesto - 如果指定,則符合條件的應用程式必須與與實體類型相關聯的給定實體相關或不相關。relatesto 表示為下列形式的表達式:isrelatedto - 如果指定,則符合條件的應用程式必須與與實體類型關聯的特定實體相關或不相關。isrelatedto 的表示方式與 relatesto 相同。infofilters - 如果指定,則符合條件的應用程式必須與特定資訊金鑰完全符合,且必須等於或不等於特定值。資訊金鑰是字串,但值可以是任何物件。infofilters 的表示方式為下列形式的表達式:conffilters - 如果指定,則符合條件的應用程式必須與特定設定名稱完全符合,且必須等於或不等於特定設定值。設定名稱和值都必須是字串。conffilters 的表示方式與 infofilters 相同。metricfilters - 如果指定,則符合條件的應用程式必須與特定指標完全符合,並滿足與指標值指定的關係。指標 ID 必須是字串,指標值必須是整數值。metricfilters 的表示方式為下列形式的表達式:事件篩選器 - 如果有指定,配對的應用程式必須包含或不包含特定事件,視表達式而定。事件篩選器表示為以下形式的表達式:metricstoretrieve - 如果有指定,則會定義要擷取哪些指標,或是不擷取哪些指標並在回應中傳回。metricstoretrieve 可以是下列形式的運算式:METRICS,都會擷取指標。請注意,網址不安全的字元(例如空格)必須適當地編碼。要擷取的組態 - 如果有指定,會定義要擷取或不擷取哪些組態,並在回應中傳送回來。要擷取的組態可以是以下形式的表達式:CONFIGS,都將擷取設定檔。請注意,URL 不安全的字元(例如空格)必須適當地編碼。fields - 指定要擷取哪些欄位。fields 的可能值可以是 EVENTS、INFO、CONFIGS、METRICS、RELATES_TO、IS_RELATED_TO 和 ALL。如果指定 ALL,將會擷取所有欄位。可以使用逗號分隔清單指定多個欄位。如果未指定 fields,則回應中將傳回 app id、類型(等同於 YARN_APPLICATION)、app 建立時間和 info 欄位中的 UID。metricslimit - 如果指定,則定義要傳回的指標數量。僅在 fields 包含 METRICS/ALL 或指定 metricstoretrieve 時考量。否則會忽略。metricslimit 的最大可能值可以是 Integer 的最大值。如果未指定或值小於 1,且必須擷取指標,則 metricslimit 將視為 1,亦即傳回指標的最新單一值。metricstimestart - 如果指定,則傳回此時間戳記之後的實體指標。metricstimeend - 如果指定,則傳回此時間戳記之前的實體指標。fromid - 如果指定,則從指定的 fromid 擷取下一組應用程式實體。擷取的實體組包含指定的 fromid。fromid 應從稍早傳送的流程實體回應中與 FROM_ID 資訊金鑰關聯的值取得。[
{
"metrics": [],
"events": [],
"id": "application_1460419579913_0002",
"type": "YARN_APPLICATION",
"createdtime": 1460419580171,
"info": {
"UID": "test-cluster!sjlee!ds-date!1460419580171!application_1460419579913_0002"
"FROM_ID": "test-cluster!sjlee!ds-date!1460419580171!application_1460419579913_0002",
},
"configs": {},
"isrelatedto": {},
"relatesto": {}
}
]
使用此 API,您可以查詢由叢集和應用程式 ID 識別的單一 YARN 應用程式。如果使用不含叢集名稱的 REST 端點,則會採用 yarn-site.xml 中 yarn.resourcemanager.cluster-id 設定檔指定的叢集。流程內容資訊(例如使用者、流程名稱和執行 ID)不是強制性的,但如果在查詢參數中指定,可以避免需要額外的作業才能根據叢集和應用程式 ID 擷取流程內容資訊。
GET /ws/v2/timeline/clusters/{cluster name}/apps/{app id}
or
GET /ws/v2/timeline/apps/{app id}
userid - 如果已指定,則只會傳回屬於此使用者的應用程式。此查詢參數必須與 flowname 和 flowrunid 查詢參數一起指定,否則將會被忽略。如果未指定 userid、flowname 和 flowrunid,則在執行查詢時,我們必須根據叢集和 appid 來擷取流程內容資訊。flowname - 只會傳回屬於此流程名稱的應用程式。此查詢參數必須與 userid 和 flowrunid 查詢參數一起指定,否則將會被忽略。如果未指定 userid、flowname 和 flowrunid,則在執行查詢時,我們必須根據叢集和 appid 來擷取流程內容資訊。flowrunid - 只會傳回屬於此流程執行 ID 的應用程式。此查詢參數必須與 userid 和 flowname 查詢參數一起指定,否則將會被忽略。如果未指定 userid、flowname 和 flowrunid,則在執行查詢時,我們必須根據叢集和 appid 來擷取流程內容資訊。metricstoretrieve - 如果有指定,則會定義要擷取哪些指標,或是不擷取哪些指標並在回應中傳回。metricstoretrieve 可以是下列形式的運算式:METRICS,都會擷取指標。請注意,網址不安全的字元(例如空格)必須適當地編碼。要擷取的組態 - 如果有指定,會定義要擷取或不擷取哪些組態,並在回應中傳送回來。要擷取的組態可以是以下形式的表達式:CONFIGS,都將擷取設定檔。請注意,URL 不安全的字元(例如空格)必須適當地編碼。fields - 指定要擷取哪些欄位。fields 的可能值可以是 EVENTS、INFO、CONFIGS、METRICS、RELATES_TO、IS_RELATED_TO 和 ALL。如果指定 ALL,將會擷取所有欄位。可以使用逗號分隔清單指定多個欄位。如果未指定 fields,則回應中將傳回 app id、類型(等同於 YARN_APPLICATION)、app 建立時間和 info 欄位中的 UID。metricslimit - 如果指定,則定義要傳回的指標數量。僅在 fields 包含 METRICS/ALL 或指定 metricstoretrieve 時考量。否則會忽略。metricslimit 的最大可能值可以是 Integer 的最大值。如果未指定或值小於 1,且必須擷取指標,則 metricslimit 將視為 1,亦即傳回指標的最新單一值。metricstimestart - 如果指定,則傳回此時間戳記之後的實體指標。metricstimeend - 如果指定,則傳回此時間戳記之前的實體指標。{
"metrics": [],
"events": [],
"id": "application_1460419579913_0002",
"type": "YARN_APPLICATION",
"createdtime": 1460419580171,
"info": {
"UID": "test-cluster!sjlee!ds-date!1460419580171!application_1460419579913_0002"
},
"configs": {},
"isrelatedto": {},
"relatesto": {}
}
透過此 API,您可以查詢由叢集 ID、應用程式 ID 和每個架構實體類型識別的通用實體。如果使用不含叢集名稱的 REST 端點,則會採用在 yarn-site.xml 中由設定檔 yarn.resourcemanager.cluster-id 指定的叢集。流程內容資訊(例如使用者、流程名稱和執行 ID)並非強制性,但如果在查詢參數中指定,則可以避免需要額外作業來根據叢集和 app ID 擷取流程內容資訊。如果符合條件的實體數目超過限制,則會傳回符合條件的最新實體(最多至限制數目)。此端點可用於查詢容器、應用程式嘗試或客戶端放入後端的任何其他通用實體。例如,我們可以透過將實體類型指定為 YARN_CONTAINER 來查詢容器,並透過將實體類型指定為 YARN_APPLICATION_ATTEMPT 來查詢應用程式嘗試。如果沒有實體符合謂詞,則會傳回一個空清單。
GET /ws/v2/timeline/clusters/{cluster name}/apps/{app id}/entities/{entity type}
or
GET /ws/v2/timeline/apps/{app id}/entities/{entity type}
userid - 如果已指定,則只會傳回屬於此使用者的實體。此查詢參數必須與 flowname 和 flowrunid 查詢參數一起指定,否則將會被忽略。如果未指定 userid、flowname 和 flowrunid,則在執行查詢時,我們必須根據叢集和 appid 來擷取流程內容資訊。flowname - 如果已指定,則只會傳回屬於此流程名稱的實體。此查詢參數必須與 userid 和 flowrunid 查詢參數一起指定,否則將會被忽略。如果未指定 userid、flowname 和 flowrunid,則在執行查詢時,我們必須根據叢集和 appid 來擷取流程內容資訊。flowrunid - 如果已指定,則只會傳回屬於此流程執行 ID 的實體。此查詢參數必須與 userid 和 flowname 查詢參數一起指定,否則將會被忽略。如果未指定 userid、flowname 和 flowrunid,則在執行查詢時,我們必須根據叢集和 appid 來擷取流程內容資訊。限制 - 如果指定,則定義要傳回的實體數量。限制的最大可能值為 Long 的最大值。如果未指定或值小於 0,則限制將視為 100。建立時間開始 - 如果指定,則只會傳回在此時間戳記之後建立的實體。建立時間結束 - 如果指定,則只會傳回在此時間戳記之前建立的實體。關聯至 - 如果指定,則符合條件的實體必須與與實體類型關聯的特定實體關聯或不關聯。關聯至表示為下列形式的表達式與其相關 - 如果指定,則符合條件的實體必須與與實體類型關聯的特定實體相關或不相關。與其相關的表示形式與關聯至相同。資訊篩選器 - 如果指定,則符合條件的實體必須與指定的資訊金鑰完全相符,且必須等於或不等於指定的值。資訊金鑰為字串,但值可以是任何物件。資訊篩選器表示為下列形式的表達式設定篩選器 - 如果指定,則符合條件的實體必須與指定的設定名稱完全相符,且必須等於或不等於指定的設定值。設定名稱和值都必須是字串。設定篩選器的表示形式與資訊篩選器相同。指標篩選器 - 如果指定,則符合條件的實體必須與指定的指標完全相符,且必須符合指標值指定的關係。指標 ID 必須是字串,指標值必須是整數值。指標篩選器表示為下列形式的表達式事件篩選器 - 如果指定,則符合條件的實體必須包含或不包含指定的事件,視表達式而定。事件篩選器表示為下列形式的表達式metricstoretrieve - 如果有指定,則會定義要擷取哪些指標,或是不擷取哪些指標並在回應中傳回。metricstoretrieve 可以是下列形式的運算式:METRICS,都會擷取指標。請注意,網址不安全的字元(例如空格)必須適當地編碼。要擷取的組態 - 如果有指定,會定義要擷取或不擷取哪些組態,並在回應中傳送回來。要擷取的組態可以是以下形式的表達式:CONFIGS,都將擷取設定檔。請注意,URL 不安全的字元(例如空格)必須適當地編碼。欄位 - 指定要擷取的欄位。欄位的可能值可以是 事件、資訊、設定、指標、關聯至、與其相關 和 全部。如果指定 全部,將會擷取所有欄位。多個欄位可以用逗號分隔的清單指定。如果未指定欄位,則回應中將會傳回資訊欄位中的實體 ID、實體類型、建立時間和 UID。metricslimit - 如果指定,則定義要傳回的指標數量。僅在 fields 包含 METRICS/ALL 或指定 metricstoretrieve 時考量。否則會忽略。metricslimit 的最大可能值可以是 Integer 的最大值。如果未指定或值小於 1,且必須擷取指標,則 metricslimit 將視為 1,亦即傳回指標的最新單一值。metricstimestart - 如果指定,則傳回此時間戳記之後的實體指標。metricstimeend - 如果指定,則傳回此時間戳記之前的實體指標。fromid - 如果指定,則從指定的 fromid 擷取下一組一般實體。擷取的實體組包含指定的 fromid。fromid 應取自先前傳送的流程實體回應中與 FROM_ID 資訊金鑰關聯的值。[
{
"metrics": [ ],
"events": [ ],
"type": "YARN_APPLICATION_ATTEMPT",
"id": "appattempt_1465246237936_0001_000001",
"createdtime": 1465246358873,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!application_1465246237936_0001!YARN_APPLICATION_ATTEMPT!appattempt_1465246237936_0001_000001"
"FROM_ID": "yarn-cluster!sjlee!ds-date!1460419580171!application_1465246237936_0001!YARN_APPLICATION_ATTEMPT!0!appattempt_1465246237936_0001_000001"
},
"relatesto": { }
},
{
"metrics": [ ],
"events": [ ],
"type": "YARN_APPLICATION_ATTEMPT",
"id": "appattempt_1465246237936_0001_000002",
"createdtime": 1465246359045,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!application_1465246237936_0001!YARN_APPLICATION_ATTEMPT!appattempt_1465246237936_0001_000002"
"FROM_ID": "yarn-cluster!sjlee!ds-date!1460419580171!application_1465246237936_0001!YARN_APPLICATION_ATTEMPT!0!appattempt_1465246237936_0001_000002"
},
"relatesto": { }
}
]
使用此 API,您可以根據由叢集 ID、doAsUser 和實體類型識別的使用者查詢一般實體。如果使用不含叢集名稱的 REST 端點,則會採用 yarn-site.xml 中 yarn.resourcemanager.cluster-id 設定指定的叢集。如果符合條件的實體數量超過限制,則會傳回最多符合限制的最新實體。此端點可用於查詢客戶端放入後端的實體。例如,我們可以透過指定實體類型為 TEZ_DAG_ID 來查詢使用者實體。如果沒有任何實體符合謂詞,則會傳回一個空清單。注意:截至目前,我們只能查詢已發布且 doAsUser 與應用程式擁有者不同的實體。
GET /ws/v2/timeline/clusters/{cluster name}/users/{userid}/entities/{entitytype}
or
GET /ws/v2/timeline/users/{userid}/entities/{entitytype}
限制 - 如果指定,則定義要傳回的實體數量。限制的最大可能值為 Long 的最大值。如果未指定或值小於 0,則限制將視為 100。建立時間開始 - 如果指定,則只會傳回在此時間戳記之後建立的實體。建立時間結束 - 如果指定,則只會傳回在此時間戳記之前建立的實體。關聯至 - 如果指定,則符合條件的實體必須與與實體類型關聯的特定實體關聯或不關聯。關聯至表示為下列形式的表達式與其相關 - 如果指定,則符合條件的實體必須與與實體類型關聯的特定實體相關或不相關。與其相關的表示形式與關聯至相同。資訊篩選器 - 如果指定,則符合條件的實體必須與指定的資訊金鑰完全相符,且必須等於或不等於指定的值。資訊金鑰為字串,但值可以是任何物件。資訊篩選器表示為下列形式的表達式設定篩選器 - 如果指定,則符合條件的實體必須與指定的設定名稱完全相符,且必須等於或不等於指定的設定值。設定名稱和值都必須是字串。設定篩選器的表示形式與資訊篩選器相同。指標篩選器 - 如果指定,則符合條件的實體必須與指定的指標完全相符,且必須符合指標值指定的關係。指標 ID 必須是字串,指標值必須是整數值。指標篩選器表示為下列形式的表達式事件篩選器 - 如果指定,則符合條件的實體必須包含或不包含指定的事件,視表達式而定。事件篩選器表示為下列形式的表達式metricstoretrieve - 如果有指定,則會定義要擷取哪些指標,或是不擷取哪些指標並在回應中傳回。metricstoretrieve 可以是下列形式的運算式:METRICS,都會擷取指標。請注意,網址不安全的字元(例如空格)必須適當地編碼。要擷取的組態 - 如果有指定,會定義要擷取或不擷取哪些組態,並在回應中傳送回來。要擷取的組態可以是以下形式的表達式:CONFIGS,都將擷取設定檔。請注意,URL 不安全的字元(例如空格)必須適當地編碼。欄位 - 指定要擷取的欄位。欄位的可能值可以是 事件、資訊、設定、指標、關聯至、與其相關 和 全部。如果指定 全部,將會擷取所有欄位。多個欄位可以用逗號分隔的清單指定。如果未指定欄位,則回應中將會傳回資訊欄位中的實體 ID、實體類型、建立時間和 UID。metricslimit - 如果指定,則定義要傳回的指標數量。僅在 fields 包含 METRICS/ALL 或指定 metricstoretrieve 時考量。否則會忽略。metricslimit 的最大可能值可以是 Integer 的最大值。如果未指定或值小於 1,且必須擷取指標,則 metricslimit 將視為 1,亦即傳回指標的最新單一值。metricstimestart - 如果指定,則傳回此時間戳記之後的實體指標。metricstimeend - 如果指定,則傳回此時間戳記之前的實體指標。fromid - 如果指定,則從指定的 fromid 擷取下一組一般實體。擷取的實體組包含指定的 fromid。fromid 應取自先前傳送的流程實體回應中與 FROM_ID 資訊金鑰關聯的值。[
{
"metrics": [ ],
"events": [ ],
"type": "TEZ_DAG_ID",
"id": "dag_1465246237936_0001_000001",
"createdtime": 1465246358873,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!sjlee!TEZ_DAG_ID!0!dag_1465246237936_0001_000001"
"FROM_ID": "sjlee!yarn-cluster!TEZ_DAG_ID!0!dag_1465246237936_0001_000001"
},
"relatesto": { }
},
{
"metrics": [ ],
"events": [ ],
"type": "TEZ_DAG_ID",
"id": "dag_1465246237936_0001_000002",
"createdtime": 1465246359045,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!sjlee!TEZ_DAG_ID!0!dag_1465246237936_0001_000002!userX"
"FROM_ID": "sjlee!yarn-cluster!TEZ_DAG_ID!0!dag_1465246237936_0001_000002!userX"
},
"relatesto": { }
}
]
使用此 API,您可以查詢由叢集 ID、應用程式 ID、每個架構實體類型和實體 ID 識別的特定一般實體。如果使用不帶叢集名稱的 REST 端點,則會採用在 yarn-site.xml 中由設定檔 yarn.resourcemanager.cluster-id 指定的叢集。流程內容資訊,例如使用者、流程名稱和執行 ID 不是強制性的,但如果在查詢參數中指定,則可以避免需要額外的操作來根據叢集和應用程式 ID 擷取流程內容資訊。此端點可 used to query a single container, application attempt or any other generic entity which clients put into the backend. For instance, we can query a specific YARN container by specifying entity type as YARN_CONTAINER and giving entity ID as container ID. Similarly, application attempt can be queried by specifying entity type as YARN_APPLICATION_ATTEMPT and entity ID being the application attempt ID.
GET /ws/v2/timeline/clusters/{cluster name}/apps/{app id}/entities/{entity type}/{entity id}
or
GET /ws/v2/timeline/apps/{app id}/entities/{entity type}/{entity id}
userid - 如果指定,實體必須屬於此使用者。此查詢參數必須與 flowname 和 flowrunid 查詢參數一起指定,否則將會被忽略。如果未指定 userid、flowname 和 flowrunid,我們必須在執行查詢時根據叢集和 appid 擷取流程內容資訊。flowname - 如果指定,實體必須屬於此流程名稱。此查詢參數必須與 userid 和 flowrunid 查詢參數一起指定,否則將會被忽略。如果未指定 userid、flowname 和 flowrunid,我們必須在執行查詢時根據叢集和 appid 擷取流程內容資訊。flowrunid - 如果指定,實體必須屬於此流程執行 ID。此查詢參數必須與 userid 和 flowname 查詢參數一起指定,否則將會被忽略。如果未指定 userid、flowname 和 flowrunid,我們必須在執行查詢時根據叢集和 appid 擷取流程內容資訊。metricstoretrieve - 如果有指定,則會定義要擷取哪些指標,或是不擷取哪些指標並在回應中傳回。metricstoretrieve 可以是下列形式的運算式:METRICS,都會擷取指標。請注意,網址不安全的字元(例如空格)必須適當地編碼。要擷取的組態 - 如果有指定,會定義要擷取或不擷取哪些組態,並在回應中傳送回來。要擷取的組態可以是以下形式的表達式:CONFIGS,都將擷取設定檔。請注意,URL 不安全的字元(例如空格)必須適當地編碼。欄位 - 指定要擷取的欄位。欄位的可能值可以是 事件、資訊、設定、指標、關聯至、與其相關 和 全部。如果指定 全部,將會擷取所有欄位。多個欄位可以用逗號分隔的清單指定。如果未指定欄位,則回應中將會傳回資訊欄位中的實體 ID、實體類型、建立時間和 UID。metricslimit - 如果指定,則定義要傳回的指標數量。僅在 fields 包含 METRICS/ALL 或指定 metricstoretrieve 時考量。否則會忽略。metricslimit 的最大可能值可以是 Integer 的最大值。如果未指定或值小於 1,且必須擷取指標,則 metricslimit 將視為 1,亦即傳回指標的最新單一值。metricstimestart - 如果指定,則傳回此時間戳記之後的實體指標。metricstimeend - 如果指定,則傳回此時間戳記之前的實體指標。entityidprefix 定義要擷取的實體的 ID 前置詞。如果指定,則實體擷取會更快。{
"metrics": [ ],
"events": [ ],
"type": "YARN_APPLICATION_ATTEMPT",
"id": "appattempt_1465246237936_0001_000001",
"createdtime": 1465246358873,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!application_1465246237936_0001!YARN_APPLICATION_ATTEMPT!0!appattempt_1465246237936_0001_000001"
"FROM_ID": "yarn-cluster!sjlee!ds-date!1460419580171!application_1465246237936_0001!YARN_APPLICATION_ATTEMPT!0!appattempt_1465246237936_0001_000001"
},
"relatesto": { }
}
透過此 API,您可以根據群集 ID、doAsUser、實體類型和實體 ID 查詢由使用者識別的通用實體。如果使用沒有群集名稱的 REST 端點,則會採用在 yarn-site.xml 中的設定 yarn.resourcemanager.cluster-id 所指定的群集。如果符合條件的實體數量超過限制,則會傳回最多符合限制的最新實體。此端點可用於查詢客戶端放入後端的通用實體。例如,我們可以透過將實體類型指定為 TEZ_DAG_ID 來查詢使用者實體。如果沒有任何實體符合謂詞,則會傳回一個空清單。注意:截至今日,我們只能查詢由 doAsUser 發布的實體,而 doAsUser 與應用程式擁有者不同。
GET /ws/v2/timeline/clusters/{cluster name}/users/{userid}/entities/{entitytype}/{entityid}
or
GET /ws/v2/timeline/users/{userid}/entities/{entitytype}/{entityid}
metricstoretrieve - 如果有指定,則會定義要擷取哪些指標,或是不擷取哪些指標並在回應中傳回。metricstoretrieve 可以是下列形式的運算式:METRICS,都會擷取指標。請注意,網址不安全的字元(例如空格)必須適當地編碼。要擷取的組態 - 如果有指定,會定義要擷取或不擷取哪些組態,並在回應中傳送回來。要擷取的組態可以是以下形式的表達式:CONFIGS,都將擷取設定檔。請注意,URL 不安全的字元(例如空格)必須適當地編碼。欄位 - 指定要擷取的欄位。欄位的可能值可以是 事件、資訊、設定、指標、關聯至、與其相關 和 全部。如果指定 全部,將會擷取所有欄位。多個欄位可以用逗號分隔的清單指定。如果未指定欄位,則回應中將會傳回資訊欄位中的實體 ID、實體類型、建立時間和 UID。metricslimit - 如果指定,則定義要傳回的指標數量。僅在 fields 包含 METRICS/ALL 或指定 metricstoretrieve 時考量。否則會忽略。metricslimit 的最大可能值可以是 Integer 的最大值。如果未指定或值小於 1,且必須擷取指標,則 metricslimit 將視為 1,亦即傳回指標的最新單一值。metricstimestart - 如果指定,則傳回此時間戳記之後的實體指標。metricstimeend - 如果指定,則傳回此時間戳記之前的實體指標。fromid - 如果指定,則從指定的 fromid 擷取下一組一般實體。擷取的實體組包含指定的 fromid。fromid 應取自先前傳送的流程實體回應中與 FROM_ID 資訊金鑰關聯的值。[
{
"metrics": [ ],
"events": [ ],
"type": "TEZ_DAG_ID",
"id": "dag_1465246237936_0001_000001",
"createdtime": 1465246358873,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!sjlee!TEZ_DAG_ID!0!dag_1465246237936_0001_000001!userX"
"FROM_ID": "sjlee!yarn-cluster!TEZ_DAG_ID!0!dag_1465246237936_0001_000001!userX"
},
"relatesto": { }
}
]
透過此 API,您可以查詢給定應用程式 ID 的可用實體類型集合。如果使用沒有群集名稱的 REST 端點,則會採用在 yarn-site.xml 中的設定 yarn.resourcemanager.cluster-id 所指定的群集。如果未指定使用者 ID、流程名稱和流程執行 ID(這些是選用的查詢參數),則會根據儲存在基礎儲存實作中的流程內容資訊,根據應用程式 ID 和群集 ID 查詢這些資訊。
GET /ws/v2/timeline/apps/{appid}/entity-types
or
GET /ws/v2/timeline/clusters/{clusterid}/apps/{appid}/entity-types
使用者 ID - 如果有指定,則實體必須屬於此使用者。此查詢參數必須與 flowname 和 flowrunid 查詢參數一起指定,否則會略過此參數。如果未指定使用者 ID、流程名稱和流程執行 ID,則時間軸讀取器會在執行查詢時根據群集和 appid 擷取流程內容資訊。flowname - 如果指定,實體必須屬於此流程名稱。此查詢參數必須與 userid 和 flowrunid 查詢參數一起指定,否則將會被忽略。如果未指定 userid、flowname 和 flowrunid,我們必須在執行查詢時根據叢集和 appid 擷取流程內容資訊。flowrunid - 如果指定,實體必須屬於此流程執行 ID。此查詢參數必須與 userid 和 flowname 查詢參數一起指定,否則將會被忽略。如果未指定 userid、flowname 和 flowrunid,我們必須在執行查詢時根據叢集和 appid 擷取流程內容資訊。{
YARN_APPLICATION_ATTEMPT,
YARN_CONTAINER,
MAPREDUCE_JOB,
MAPREDUCE_TASK,
MAPREDUCE_TASK_ATTEMPT
}
TimelineService v.2 支援提供歷史應用程式的彙總記錄。若要啟用此功能,請在 yarn-site.xml 中將 yarn.log.server.web-service.url 設定為 ${yarn .timeline-service.hostname}:8188/ws/v2/applicationlog