
YARN 已知可擴充至數千個節點。 YARN 的可擴充性由資源管理員決定,且與節點數、活躍應用程式、活躍容器以及心跳頻率(節點和應用程式)成正比。降低心跳頻率可以提高可擴充性,但會損害使用率(請參閱舊的 Hadoop 1.x 經驗)。本文檔描述了一種基於聯盟的方法,透過聯盟多個 YARN 子叢集,將單一 YARN 叢集擴充至數萬個節點。建議的方法是將大型(10-100k 節點)叢集分割成較小的單元,稱為子叢集,每個子叢集都有自己的 YARN RM 和運算節點。聯盟系統將串連這些子叢集,並讓它們對應用程式顯示為一個大型 YARN 叢集。在此聯盟環境中執行的應用程式將看到一個單一的龐大 YARN 叢集,並能夠在聯盟叢集的任何節點上排程任務。在底層,聯盟系統將與子叢集資源管理員協商,並提供資源給應用程式。目標是允許個別作業無縫「跨越」子叢集。
此設計在結構上是可擴充的,因為我們限制了每個 RM 負責的節點數量,並且適當的政策會試圖確保大多數應用程式會駐留在單一子叢集中,因此每個 RM 會看到的應用程式數量也是受限制的。這表示我們可以透過簡單地新增子叢集(因為它們之間幾乎不需要協調)來幾乎線性地擴充。此架構可以在每個子叢集中提供非常嚴格的排程不變式執行(只需從 YARN 繼承),而跨子叢集的持續重新平衡會(較不嚴格地)執行,以確保這些屬性在全球層級上也受到尊重(例如,如果子叢集失去大量的節點,我們可以將佇列重新對應到其他子叢集,以確保在受損子叢集上執行的使用者不會受到不公平的影響)。
聯盟被設計為現有 YARN 程式碼庫上方的「層」,核心 YARN 機制的變更有限。
假設
已知 OSS YARN 可以擴充到大約數千個節點。建議的架構利用了將許多此類較小的 YARN 叢集(稱為子叢集)聯盟成一個包含數萬個節點的較大聯盟 YARN 叢集的概念。在此聯盟環境中執行的應用程式會看到一個統一的大型 YARN 叢集,並且能夠在叢集中的任何節點上排程工作。在底層,聯盟系統會與子叢集 RM 協商,並提供資源給應用程式。圖 1 中的邏輯架構顯示了組成聯盟叢集的主要元件,說明如下。
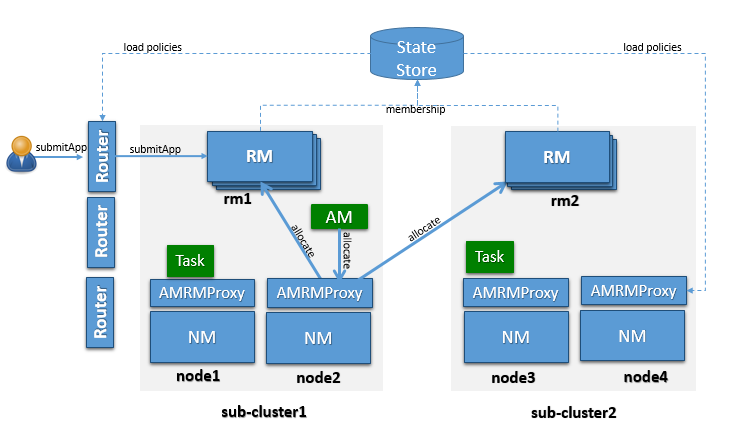
子叢集是一個最多有數千個節點的 YARN 叢集。子叢集的確切大小將考慮部署/維護的容易性、與網路或可用性區域的一致性以及一般最佳實務。
子叢集 YARN RM 將在開啟工作保留高可用性的情況下執行,亦即我們應該能夠容忍 YARN RM、NM 故障,且中斷程度最低。如果整個子叢集受損,外部機制將確保工作會在不同的子叢集中重新提交(這最終可以包含在聯盟設計中)。
子叢集也是聯盟環境中的可擴充性單位。我們可以透過新增一個或多個子叢集來擴充聯盟環境。
注意:每個子叢集在設計上都是一個功能完備的 YARN RM,它對聯合的貢獻可以設定為其整體容量的一部分,亦即子叢集可以「部分」承諾聯合,同時保留以完全本機方式提供部分容量的能力。
YARN 應用程式提交至其中一個路由器,路由器會套用路由政策(從政策儲存取得),查詢狀態儲存的子叢集 URL,並將應用程式提交要求重新導向至適當的子叢集 RM。我們稱呼工作開始執行的子叢集為「家目錄子叢集」,而工作跨越的所有其他子叢集則稱為「次要子叢集」。路由器對外公開 ApplicationClientProtocol,透明地隱藏多個 RM 的存在。為達成此目的,路由器也會將應用程式與其家目錄子叢集之間的對應關係持續儲存到狀態儲存中。這讓路由器能以軟狀態支援使用者要求,因為任何路由器都可以復原此應用程式對應到家目錄子叢集的對應關係,並將要求直接導向正確的 RM,而無須廣播。建議使用效能快取和會話黏著性。聯合的狀態(包括應用程式和節點)會透過 Web UI 公開。
AMRMProxy 是允許應用程式跨子叢集擴充和執行的關鍵元件。AMRMProxy 在所有 NM 電腦上執行,並透過實作 ApplicationMasterProtocol,作為 AM 的 YARN RM 代理。不允許應用程式直接與子叢集 RM 通訊。系統會強制應用程式只連線到 AMRMProxy 端點,而端點會提供對多個 YARN RM 的透明存取(透過動態路由/分割/合併通訊)。在任何時間點,工作都可以跨越一個家目錄子叢集和多個次要子叢集,但 AMRMProxy 中運作的政策會嘗試限制每個工作的足跡,以將排程基礎架構的負擔降至最低(詳細內容請見擴充性/負載區段)。ARMMProxy 的攔截器鏈架構顯示在圖中。
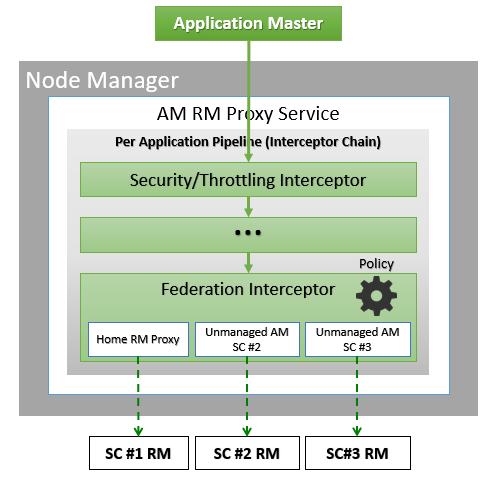
AMRMProxy 的角色
全域政策產生器監督整個聯盟,並確保系統始終正確配置和調整。一個關鍵設計點是叢集可用性不依賴於持續運作的 GPG。GPG 持續運作,但與所有叢集作業脫節,並提供我們一個獨特的觀點,允許強制執行全域不變數、影響負載平衡、觸發將進行維護的子叢集的排放等。更精確地說,GPG 將更新使用者容量配置到子叢集對應、並更罕見地變更在路由器、AMRMProxy(和可能的 RM)中執行的政策。
如果 GPG 不可用,叢集作業將從 GPG 發布政策的最後時間繼續,而長期不可用可能表示平衡、最佳叢集使用率和全域不變數的一些理想屬性可能會消失,計算和資料存取將不會受到影響。
注意:在目前的實作中,GPG 是手動調整程序,僅透過 CLI(YARN-3657)公開。
聯盟系統的這部分是 YARN-5597 中未來工作的部分。
聯盟狀態定義了將多個個別子叢集鬆散結合到單一大型聯盟叢集所需的附加狀態。這包括以下資訊
YARN RM 成員持續對狀態儲存進行心跳,以保持運作並發布其目前的效能/負載資訊。此資訊由全球政策產生器 (GPG) 用於做出適當的政策決策。此外,此資訊可由路由器用於選取最佳的家用次叢集。此機制讓我們能透過新增或移除次叢集,動態地擴充/縮減「叢集艦隊」。這也讓每個次叢集能輕鬆維護。這是需要新增到 YARN RM 的新功能,但機制很清楚,因為它類似於個別的 YARN RM HA。
應用程式主控程式 (AM) 執行的次叢集稱為應用程式的「家用次叢集」。AM 不限於家用次叢集的資源,但也可以要求其他次叢集(稱為次要次叢集)的資源。聯邦環境將定期設定和調整,以便在 AM 放置在次叢集時,它應該能夠在家用次叢集找到大部分資源。只有在某些情況下,它才需要要求其他次叢集的資源。
聯邦政策儲存是一個邏輯上獨立的儲存(儘管它可能由相同的實體元件支援),其中包含有關如何將應用程式和資源要求路由到不同次叢集的資訊。目前的實作提供多項政策,從隨機/雜湊/循環/優先順序到更精密的政策,這些政策考量次叢集負載和要求的區域性需求。
當提交應用程式時,系統將決定最適合執行應用程式的次叢集,我們稱之為應用程式的家用次叢集。AM 與 RM 之間的所有通訊將透過在 AM 機器上本地執行的 AMRMProxy 代理。AMRMProxy 公開與 YARN RM 相同的 ApplicationMasterService 協定端點。AM 可以使用儲存層公開的區域性資訊來要求容器。在理想情況下,應用程式將被放置在一個次叢集上,其中應用程式所需的所有資源和資料都可用,但如果它確實需要其他次叢集節點上的容器,AMRMProxy 將與那些次叢集的 RM 透明協商並提供資源給應用程式,從而使應用程式能將整個聯邦環境視為一個龐大的 YARN 叢集。AMRMProxy、全球政策產生器 (GPG) 和路由器共同合作,讓這一切順利進行。
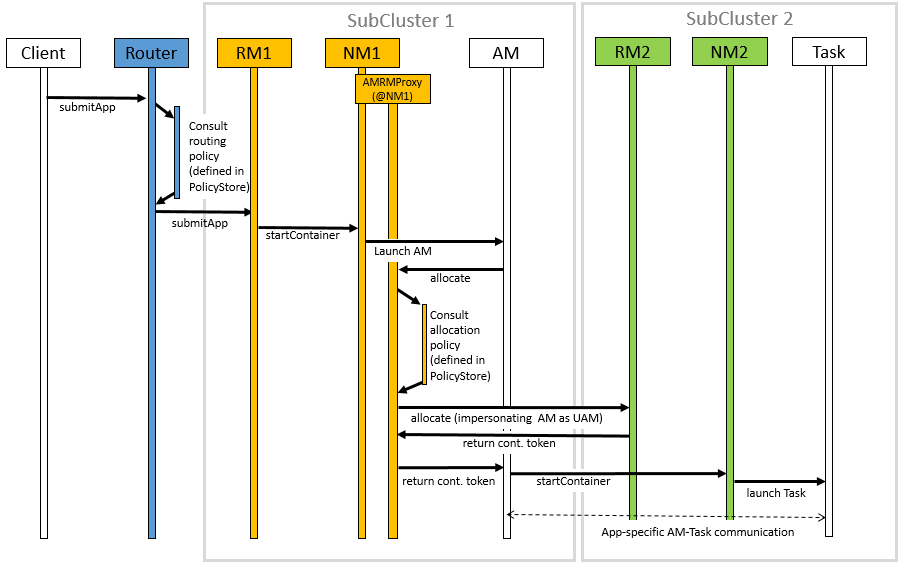
此圖顯示下列工作執行流程的順序圖
若要設定 YARN 以使用 Federation,請在 conf/yarn-site.xml 中設定下列屬性
這些是一般設定,應出現在聯盟中每部電腦的 conf/yarn-site.xml 中。
| 屬性 | 範例 | 說明 |
|---|---|---|
yarn.federation.enabled |
true |
是否啟用聯盟 |
yarn.resourcemanager.cluster-id |
<unique-subcluster-id> |
此 RM 的唯一子聯盟識別碼(與用於 HA 的識別碼相同)。 |
目前,我們支援 State-Store 的 ZooKeeper 和 SQL 實作。
注意:State-Store 實作必須始終覆寫為下列其中之一。
ZooKeeper:必須設定 Hadoop 的 ZooKeeper 設定
| 屬性 | 範例 | 說明 |
|---|---|---|
yarn.federation.state-store.class |
org.apache.hadoop.yarn.server.federation.store.impl.ZookeeperFederationStateStore |
要使用的 State-Store 類型。 |
hadoop.zk.address |
host:port |
ZooKeeper 組合的位址。 |
SQL:必須設定下列參數
| 屬性 | 範例 | 說明 |
|---|---|---|
yarn.federation.state-store.class |
org.apache.hadoop.yarn.server.federation.store.impl.SQLFederationStateStore |
要使用的 State-Store 類型。 |
yarn.federation.state-store.sql.url |
jdbc:mysql://<host>:<port>/FederationStateStore |
對於 SQLFederationStateStore,儲存狀態的資料庫名稱。 |
yarn.federation.state-store.sql.jdbc-class |
com.mysql.jdbc.jdbc2.optional.MysqlDataSource |
對於 SQLFederationStateStore,要使用的 jdbc 類別。 |
yarn.federation.state-store.sql.username |
<dbuser> |
對於 SQLFederationStateStore,資料庫連線的使用者名稱。 |
yarn.federation.state-store.sql.password |
<dbpass> |
對於 SQLFederationStateStore,資料庫連線的密碼。 |
我們提供 MySQL 和 Microsoft SQL Server 的指令碼。
對於 MySQL,必須從 MVN Repository 下載最新 jar 版本 5.x,並將其新增至 CLASSPATH。然後,執行資料庫中的下列 SQL 指令碼,即可建立資料庫架構
在同一個目錄中,我們提供指令碼,用於刪除儲存程序、表格、使用者和資料庫。
注意:FederationStateStoreUser.sql 定義資料庫的預設使用者/密碼,我們強烈建議將其設定為適當的強密碼。
對於 SQL-Server,程序類似,但 jdbc 驅動程式已包含在內。SQL-Server 指令碼位於 sbin/FederationStateStore/SQLServer/ 中。
| 屬性 | 範例 | 說明 |
|---|---|---|
yarn.federation.failover.enabled |
true |
是否應在每個子聯盟中考慮 RM 故障轉移而重試。 |
yarn.federation.blacklist-subclusters |
<子叢集 ID> |
黑名單子叢集清單,可用於停用子叢集 |
yarn.federation.policy-manager |
org.apache.hadoop.yarn.server.federation.policies.manager.WeightedLocalityPolicyManager |
政策管理員的選擇決定應用程式和資源請求如何透過系統路由。 |
yarn.federation.policy-manager-params |
<二進位> |
設定政策的載荷。在我們的範例中,路由器和 amrmproxy 政策的權重組。這通常是透過序列化已透過程式設定的 policymanager,或透過使用 .json 序列化格式填入狀態儲存來產生。 |
yarn.federation.subcluster-resolver.class |
org.apache.hadoop.yarn.server.federation.resolver.DefaultSubClusterResolverImpl |
用於解析節點屬於哪個子叢集,以及哪個子叢集(們)屬於機架的類別。 |
yarn.federation.machine-list |
<機器清單檔案路徑> |
SubClusterResolver 使用的機器清單檔案路徑。檔案的每一行都是具有子叢集和機架資訊的節點。以下是範例 node1, subcluster1, rack1 node2, subcluster2, rack1 node3, subcluster3, rack2 node4, subcluster3, rack2 |
這些是應該出現在每個 ResourceManager 中的 conf/yarn-site.xml 中的額外設定。
| 屬性 | 範例 | 說明 |
|---|---|---|
yarn.resourcemanager.epoch |
<唯一時期> |
時期的種子值。這用於保證不同 RM 產生的容器 ID 的唯一性。因此,它在子叢集之間必須是唯一的,並且要「間隔良好」以允許會增加時期的失敗。1000 的增量允許大量的子叢集,並實際確保幾乎沒有衝突的機會(只有當容器在一個 RM 的 1000 次重新啟動中仍然存活,而下一個 RM 從未重新啟動,且應用程式要求更多容器時,才會發生衝突)。 |
選擇性
| 屬性 | 範例 | 說明 |
|---|---|---|
yarn.federation.state-store.heartbeat-interval-secs |
60 |
RM 向中央狀態儲存報告其成員資格到聯盟的速率。 |
這些是應該出現在每個 Router 中的 conf/yarn-site.xml 中的額外設定。
| 屬性 | 範例 | 說明 |
|---|---|---|
yarn.router.bind-host |
0.0.0.0 |
將路由器繫結到的主機 IP。伺服器將繫結到的實際位址。如果設定這個選用位址,RPC 和 Webapp 伺服器將分別繫結到這個位址和 yarn.router.*.address 中指定的埠。這對於透過設定為 0.0.0.0 來讓 Router 偵聽所有介面最為有用。 |
yarn.router.clientrm.interceptor-class.pipeline |
org.apache.hadoop.yarn.server.router.clientrm.FederationClientInterceptor |
當與用戶端介面時,在路由器上執行的攔截器類別的逗號分隔清單。此管線的最後步驟必須是 Federation Client Interceptor。 |
選擇性
| 屬性 | 範例 | 說明 |
|---|---|---|
yarn.router.hostname |
0.0.0.0 |
路由器主機名稱。 |
yarn.router.clientrm.address |
0.0.0.0:8050 |
路由器用戶端地址。 |
yarn.router.webapp.address |
0.0.0.0:8089 |
路由器的 Webapp 地址。 |
yarn.router.admin.address |
0.0.0.0:8052 |
路由器的管理員地址。 |
yarn.router.webapp.https.address |
0.0.0.0:8091 |
路由器的安全 Webapp 地址。 |
yarn.router.submit.retry |
3 |
在我們放棄之前,路由器中的重試次數。 |
yarn.federation.statestore.max-connections |
10 |
這是每個路由器與狀態儲存建立的並行連線的最大數量。 |
yarn.federation.cache-ttl.secs |
60 |
路由器快取資訊,這是快取失效前的保留時間。 |
yarn.router.webapp.interceptor-class.pipeline |
org.apache.hadoop.yarn.server.router.webapp.FederationInterceptorREST |
透過 REST 介面與用戶端介面時,在路由器上執行的攔截器類別的逗號分隔清單。此管線的最後步驟必須是 Federation Interceptor REST。 |
這些是應該出現在每個節點管理員的 conf/yarn-site.xml 中的額外設定檔。
| 屬性 | 範例 | 說明 |
|---|---|---|
yarn.nodemanager.amrmproxy.enabled |
true |
AMRMProxy 是否已啟用。 |
yarn.nodemanager.amrmproxy.interceptor-class.pipeline |
org.apache.hadoop.yarn.server.nodemanager.amrmproxy.FederationInterceptor |
要在 amrmproxy 上執行的攔截器的逗號分隔清單。對於聯盟,管線中的最後步驟應該是 FederationInterceptor。 |
選擇性
| 屬性 | 範例 | 說明 |
|---|---|---|
yarn.nodemanager.amrmproxy.ha.enable |
true |
AMRMProxy HA 是否已啟用以支援多個應用程式嘗試。 |
yarn.federation.statestore.max-connections |
1 |
每個 AMRMProxy 與狀態儲存之間的並行連線最大數量。此值通常低於路由器,因為我們有許多 AMRMProxy 可以快速燒毀許多資料庫連線。 |
yarn.federation.cache-ttl.secs |
300 |
AMRMProxy 快取的保留時間。通常大於路由器,因為 AMRMProxy 的數量很大,而且我們希望限制集中式狀態儲存的負載。 |
若要將工作提交到聯盟叢集,必須為提交工作的用戶端建立一組獨立的設定檔。在這些設定檔中,conf/yarn-site.xml 應具有下列額外的設定檔
| 屬性 | 範例 | 說明 |
|---|---|---|
yarn.resourcemanager.address |
<router_host>:8050 |
將在客戶端啟動的工作重新導向至路由器的客戶端 RM 埠。 |
yarn.resourcemanager.scheduler.address |
localhost:8049 |
將工作重新導向至聯合 AMRMProxy 埠。 |
群集的任何 YARN 工作都可以從上述的客戶端設定提交。若要透過聯合啟動工作,請先依據此處的說明啟動聯合中涉及的所有群集。接著,使用下列指令在路由器機器上啟動路由器
$HADOOP_HOME/bin/yarn --daemon start router
現在,讓 $HADOOP_CONF_DIR 指向上述的客戶端設定資料夾,然後以一般方式執行您的工作。上述客戶端設定資料夾中的設定會將工作導向路由器的客戶端 RM 埠,路由器在啟動後應會在該埠監聽。以下是從客戶端在聯合群集上執行 Pi 工作的範例
$HADOOP_HOME/bin/yarn jar hadoop-mapreduce-examples-3.0.0.jar pi 16 1000
此工作會提交至路由器,如上所述,路由器會使用從GPG產生的政策為工作選取一個主 RM,工作會提交至該主 RM。
這個特定範例工作的輸出應類似於
2017-07-13 16:29:25,055 INFO mapreduce.Job: Job job_1499988226739_0001 running in uber mode : false 2017-07-13 16:29:25,056 INFO mapreduce.Job: map 0% reduce 0% 2017-07-13 16:29:33,131 INFO mapreduce.Job: map 38% reduce 0% 2017-07-13 16:29:39,176 INFO mapreduce.Job: map 75% reduce 0% 2017-07-13 16:29:45,217 INFO mapreduce.Job: map 94% reduce 0% 2017-07-13 16:29:46,228 INFO mapreduce.Job: map 100% reduce 100% 2017-07-13 16:29:46,235 INFO mapreduce.Job: Job job_1499988226739_0001 completed successfully . . . Job Finished in 30.586 seconds Estimated value of Pi is 3.14250000......
也可以在路由器 Web UI 上追蹤工作的狀態,網址為 routerhost:8089。請注意,不需要變更程式碼或重新編譯輸入 jar 即可使用聯合。此外,此工作的輸出與在未聯合時執行的輸出完全相同。此外,若要充分利用聯合,請使用足夠多的對應器,以致需要多於一個群集。在上述範例中,這個數字剛好是 16。