
本指南概述 HDFS 聯盟功能,以及如何設定和管理聯盟群集。
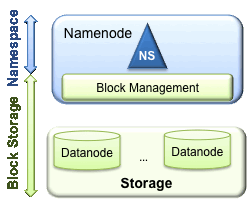
HDFS 有兩個主要層級
先前的 HDFS 架構僅允許整個叢集使用單一名稱空間。在該組態中,單一名稱節點管理名稱空間。HDFS 聯盟透過新增對 HDFS 的多個名稱節點/名稱空間支援,來解決此限制。
為了橫向擴充名稱服務,聯盟使用多個獨立的名稱節點/名稱空間。名稱節點是聯盟的;名稱節點是獨立的,不需要彼此協調。資料節點由所有名稱節點用作區塊的共用儲存。每個資料節點都會向叢集中的所有名稱節點註冊。資料節點會傳送定期心跳和區塊報告。它們也會處理來自名稱節點的指令。
使用者可以使用 ViewFs 來建立個人化名稱空間檢視。ViewFs 類似於某些 Unix/Linux 系統中的用戶端側掛載表格。
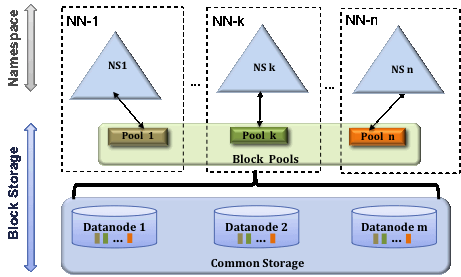
區塊池
區塊池是一組屬於單一名稱空間的區塊。資料節點會儲存叢集中所有區塊池的區塊。每個區塊池都是獨立管理的。這允許名稱空間為新區塊產生區塊 ID,而不需要與其他名稱空間協調。名稱節點故障不會阻止資料節點為叢集中的其他名稱節點提供服務。
名稱空間及其區塊池合稱為名稱空間磁碟區。它是自給自足的管理單元。當名稱節點/名稱空間被刪除時,資料節點上對應的區塊池也會被刪除。在叢集升級期間,每個名稱空間磁碟區都會作為一個單元升級。
叢集 ID
叢集 ID 識別碼用於識別叢集中的所有節點。當名稱節點被格式化時,此識別碼會提供或自動產生。此 ID 應用于將其他名稱節點格式化到叢集中。
聯合組態向下相容,讓現有的單一 Name 節點組態在不變更任何設定的情況下也能運作。新組態的設計讓叢集中的所有節點都擁有相同的組態,無須根據叢集中節點的類型部署不同的組態。
聯合會新增一個新的 NameServiceID 抽象概念。Name 節點及其對應的次要/備份/檢查點節點都屬於一個 NameServiceId。為了支援單一組態檔,Name 節點和次要/備份/檢查點組態參數會加上 NameServiceID 字尾。
步驟 1:將 dfs.nameservices 參數新增到組態中,並使用逗號分隔的 NameServiceID 清單進行組態。資料節點會使用此清單來判斷叢集中的 Name 節點。
步驟 2:針對每個 Name 節點和次要 Name 節點/備份節點/檢查點節點,將加上對應 NameServiceID 字尾的下列組態參數新增到共用組態檔中
| 守護程式 | 組態參數 |
|---|---|
| Name 節點 | dfs.namenode.rpc-address dfs.namenode.servicerpc-address dfs.namenode.http-address dfs.namenode.https-address dfs.namenode.keytab.file dfs.namenode.name.dir dfs.namenode.edits.dir dfs.namenode.checkpoint.dir dfs.namenode.checkpoint.edits.dir |
| 次要 Name 節點 | dfs.namenode.secondary.http-address dfs.secondary.namenode.keytab.file |
| 備份節點 | dfs.namenode.backup.address dfs.secondary.namenode.keytab.file |
以下是兩個 Name 節點的範例組態
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>nn-host1:rpc-port</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>nn-host1:http-port</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns1</name>
<value>snn-host1:http-port</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>nn-host2:rpc-port</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>nn-host2:http-port</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns2</name>
<value>snn-host2:http-port</value>
</property>
.... Other common configuration ...
</configuration>
步驟 1:使用下列指令格式化 Name 節點
[hdfs]$ $HADOOP_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
選擇一個不會與環境中其他叢集衝突的唯一叢集 ID。如果沒有提供叢集 ID,系統會自動產生一個唯一的 ID。
步驟 2:使用下列指令格式化其他 Name 節點
[hdfs]$ $HADOOP_HOME/bin/hdfs namenode -format -clusterId <cluster_id>
請注意,步驟 2 中的叢集 ID 必須與步驟 1 中的叢集 ID 相同。如果不同,其他 Name 節點將不會成為聯合叢集的一部分。
舊版僅支援單一 Name 節點。將叢集升級到較新版本才能啟用聯合。在升級期間,您可以提供叢集 ID,如下所示
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start namenode -upgrade -clusterId <cluster_ID>
如果未提供 cluster_id,則會自動產生。
執行下列步驟
將 dfs.nameservices 新增至組態。
使用 NameServiceID 字尾更新組態。組態金鑰名稱已在 0.20 版之後變更。您必須使用新的組態參數名稱才能使用聯合。
將新的 Namenode 相關組態新增至組態檔。
將組態檔傳播至群集中的所有節點。
啟動新的 Namenode 和次要/備份。
更新 Datanode 以挑選新增加的 Namenode,方法是在群集中的所有 Datanode 上執行下列指令
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsadmin -refreshNamenodes <datanode_host_name>:<datanode_ipc_port>
若要啟動群集,請執行下列指令
[hdfs]$ $HADOOP_HOME/sbin/start-dfs.sh
若要停止群集,請執行下列指令
[hdfs]$ $HADOOP_HOME/sbin/stop-dfs.sh
這些指令可以在任何具有 HDFS 組態的節點上執行。此指令會使用組態來判斷群集中的 Namenode,然後在這些節點上啟動 Namenode 程序。Datanode 會在 workers 檔中指定的節點上啟動。此指令碼可用作參考,用於建立您自己的指令碼以啟動和停止群集。
平衡器已變更為可與多個 Namenode 搭配使用。平衡器可以使用指令執行
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start balancer [-policy <policy>]
政策參數可以是下列任一參數
datanode - 這是預設政策。這會平衡 Datanode 層級的儲存空間。這類似於先前版本的平衡政策。
blockpool - 這會平衡區塊池層級的儲存空間,也會平衡 Datanode 層級的儲存空間。
請注意,平衡器只會平衡資料,不會平衡名稱空間。如需完整的指令使用方式,請參閱 平衡器。
停用類似於先前版本。需要停用的節點會新增至所有 Namenode 的排除檔中。每個 Namenode 都會停用其區塊池。當所有 Namenode 完成停用 Datanode 時,Datanode 即會被視為已停用。
步驟 1:若要將排除檔案分發至所有 Namenode,請使用下列指令
[hdfs]$ $HADOOP_HOME/sbin/distribute-exclude.sh <exclude_file>
步驟 2:更新所有 Namenode 以選取新的排除檔案
[hdfs]$ $HADOOP_HOME/sbin/refresh-namenodes.sh
上述指令使用 HDFS 組態來判斷叢集中的已組態 Namenode,並更新這些 Namenode 以選取新的排除檔案。
與 Namenode 狀態網頁類似,當使用聯合時,叢集 Web 主控台可用於監控聯合叢集,網址為 http://<any_nn_host:port>/dfsclusterhealth.jsp。叢集中的任何 Namenode 都可用於存取此網頁。
叢集 Web 主控台提供下列資訊
叢集摘要,顯示檔案數量、區塊數量、總組態儲存容量,以及整個叢集的可用和已用儲存空間。
Namenode 清單和摘要,其中包含每個 Namenode 的檔案數量、區塊、遺失區塊,以及正常運作和已損毀的資料節點。它也提供連結以存取每個 Namenode 的網頁使用者介面。
資料節點的停用狀態。