
估計工作資源需求仍然是企業叢集的重要且具有挑戰性的問題。這會因為工作負載日益增加的複雜性而更加嚴重,例如從傳統批次工作到互動式查詢、串流和最近的機器學習工作。這導致工作仰賴多個運算架構,例如 Tez、MapReduce、Spark 等,而叢集的共用性質進一步加劇了這個問題。目前的最新解決方案仰賴使用者專業知識來估計工作的資源需求(例如:還原器的數量或容器記憶體大小等),這既繁瑣又沒效率。
根據我們叢集工作負載的分析,我們觀察到大部分工作(超過 60%)都是重複性工作,這讓我們有機會根據工作的歷史執行記錄自動估計工作資源需求。值得注意的是,工作通常來自不同的運算架構,而且版本也可能在執行期間變更。因此,我們想要提出一個與架構無關的黑盒子解決方案,自動為重複性工作估計資源需求。
下圖說明資源估計器的實作架構。
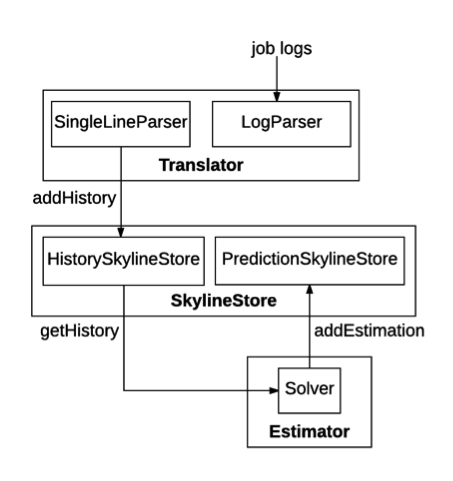
Hadoop-resourceestimator 主要包含三個模組:Translator、SkylineStore 和 Estimator。
ResourceSkyline 用於描述工作在生命週期中的資源使用率。更具體來說,它使用 RLESparseResourceAllocation (https://github.com/apache/hadoop/blob/b6e7d1369690eaf50ce9ea7968f91a72ecb74de0/hadoop-yarn-project/hadoop-yarn/hadoop-yarn-server/hadoop-yarn-server-resourcemanager/src/main/java/org/apache/hadoop/yarn/server/resourcemanager/reservation/RLESparseResourceAllocation.java) 來記錄容器配置資訊。RecurrenceId 用於識別重複執行管線的特定執行階段。一個管線可能包含多個工作,每個工作都有 ResourceSkyline 來描述其資源使用率。Translator 會剖析作業記錄,擷取其 ResourceSkylines 並將其儲存到 SkylineStore。SingleLineParser 會剖析記錄串流中的一行並擷取 ResourceSkyline。LogParser 會使用 SingleLineParser 遞迴剖析記錄串流中的每一行。請注意,記錄可能具有不同的儲存格式,因此 LogParser 會將字串串流作為輸入,而不是檔案或其他格式。由於作業記錄可能具有各種格式,因此需要不同的 SingleLineParser 實作,LogParser 會根據使用者設定啟動 SingleLineParser。目前 Hadoop-resourceestimator 提供兩個 SingleLineParser 實作:NativeSingleLineParser 支援最佳化的原生格式,而 RMSingleLineParser 會剖析 Hadoop 系統中產生的 YARN ResourceManager 記錄,因為 RM 記錄廣泛可用(在生產部署中)。SkylineStore 是 Hadoop-resourceestimator 的儲存層,包含 2 個部分。HistorySkylineStore 會儲存由 Translator 擷取的 ResourceSkylines。它支援四個動作:addHistory、deleteHistory、updateHistory 和 getHistory。addHistory 會將新的 ResourceSkylines 附加到重複執行管線,而 updateHistory 會刪除特定重複執行管線的所有 ResourceSkylines,並重新插入新的 ResourceSkylines。PredictionSkylineStore 會儲存由 Estimator 產生的預測 RLESparseResourceAllocation。它支援兩個動作:addEstimation 和 getEstimation。
目前 Hadoop-resourceestimator 提供 SkylineStore 的內建實作。
Estimator 會根據歷史執行狀況預測重複執行管線的資源需求,將預測值儲存到 SkylineStore,並對 YARN 進行重複資源預訂(YARN-5326)。Solver 會讀取特定重複執行管線的所有歷史 ResourceSkylines,並預測其新的資源需求,並包裝在 RLESparseResourceAllocation 中。目前 Hadoop-resourceestimator 提供一個 LPSOLVER 來進行預測(線性規劃模型的詳細資訊可以在論文中找到)。還有一個 BaseSolver,可將預測的資源需求轉換成 ReservationSubmissionRequest,由不同的求解器實作使用,以便在 YARN 上進行重複資源預訂。ResourceEstimationService 將 Hadoop-resourceestimator 包裝成微服務,可以在叢集中輕鬆部署。它提供一組 REST API,讓使用者可以剖析指定的作業記錄檔、查詢管線的歷史 ResourceSkylines、查詢管線的預測資源需求,以及在預測值不存在時執行 SOLVER、刪除 SkylineStore 中的 ResourceSkylines。本節將引導您使用資源估計器服務。
在此,讓 $HADOOP_ROOT 代表 Hadoop 安裝目錄。如果您自行建置 Hadoop,則 $HADOOP_ROOT 為 hadoop-dist/target/hadoop-$VERSION。資源估計器服務的位置 $ResourceEstimatorServiceHome 為 $HADOOP_ROOT/share/hadoop/tools/resourceestimator。它包含 3 個資料夾:bin、conf 和 data。請注意,使用者可以使用預設組態來使用資源估計器服務。
bin 包含資源估計器服務的執行指令碼。
conf:包含資源估計器服務的組態檔。
data 包含用於執行資源估計器服務範例的範例記錄檔。
首先,將組態檔(位於 $ResourceEstimatorServiceHome/conf/)複製到 $HADOOP_ROOT/etc/hadoop。
啟動估計器的指令碼為 start-estimator.sh。
$ cd $ResourceEstimatorServiceHome $ bin/start-estimator.sh
將啟動一個網路伺服器,使用者可以使用 REST API 使用資源估計服務。
資源估計器服務的 URI 為 http://0.0.0.0,預設服務埠為 9998(在 $ResourceEstimatorServiceHome/conf/resourceestimator-config.xml 中組態)。在 $ResourceEstimatorServiceHome/data 中,有一個範例記錄檔 resourceEstimatorService.txt,其中包含 tpch_q12 查詢作業在 2 次執行中的記錄檔。
剖析作業記錄檔:POST http://URI:port/resourceestimator/translator/LOG_FILE_DIRECTORY傳送 POST http://0.0.0.0:9998/resourceestimator/translator/data/resourceEstimatorService.txt。基礎估計器會從記錄檔中萃取 ResourceSkylines,並將它們儲存在作業歷程記錄 SkylineStore 中。
查詢工作記錄 ResourceSkylines:GET http://URI:port/resourceestimator/skylinestore/history/{pipelineId}/{runId}傳送 GET http://0.0.0.0:9998/resourceestimator/skylinestore/history/*/*,底層估計器將傳回 SkylineStore 中的所有記錄。您應該可以看到 tpch_q12 的兩次執行之 ResourceSkylines:tpch_q12_0 和 tpch_q12_1。請注意,pipelineId 和 runId 欄位都支援萬用字元運算。
預測工作的資源輪廓需求:GET http://URI:port/resourceestimator/estimator/{pipelineId}傳送 http://0.0.0.0:9998/resourceestimator/estimator/tpch_q12,底層估計器將根據其記錄 ResourceSkylines 預測新執行的工作資源需求,並將預測的資源需求儲存在 jobEstimation SkylineStore 中。
查詢工作的預測資源輪廓:GET http://URI:port/resourceestimator/skylinestore/estimation/{pipelineId}傳送 http://0.0.0.0:9998/resourceestimator/skylinestore/estimation/tpch_q12,底層估計器將傳回 tpch_q12 工作的記錄資源需求估計。請注意,對於 jobEstimation SkylineStore,它不支援萬用字元運算。
刪除工作的記錄資源輪廓:DELETE http://URI:port/resourceestimator/skylinestore/history/{pipelineId}/{runId}傳送 http://0.0.0.0:9998/resourceestimator/skylinestore/history/tpch_q12/tpch_q12_0,底層估計器將刪除 tpch_q12_0 的 ResourceSkyline 記錄。重新傳送 GET http://0.0.0.0:9998/resourceestimator/skylinestore/history/*/*,底層估計器將只傳回 tpch_q12_1 的 ResourceSkyline。
停止估計器的指令碼為 stop-estimator.sh。
$ cd $ResourceEstimatorServiceHome $ bin/stop-estimator.sh
以下提供使用資源估計器服務的範例。
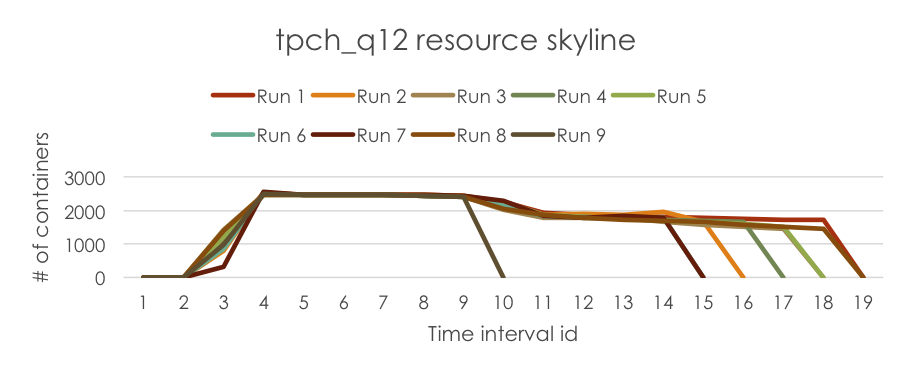
首先,我們執行 tpch_q12 工作 9 次,並在每次執行中收集工作的資源輪廓(請注意,在此範例中,我們只收集「已配置容器數量」資訊)。
接著,我們在資源估計器服務中執行記錄剖析器,從記錄中萃取 ResourceSkylines 並將它們儲存在 SkylineStore 中。工作的 ResourceSkylines 如下所示,供您參考。
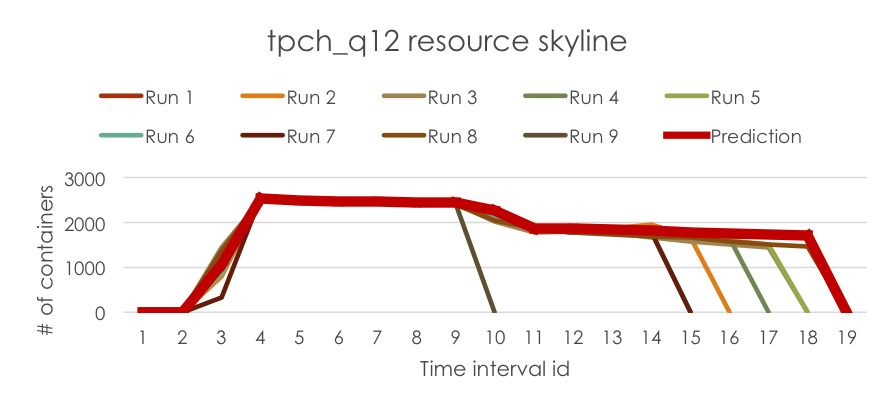
最後,我們在資源估計器服務中執行估計器,以預測新執行的資源需求,它會封裝在 RLESparseResourceAllocation 中 (https://github.com/apache/hadoop/blob/b6e7d1369690eaf50ce9ea7968f91a72ecb74de0/hadoop-yarn-project/hadoop-yarn/hadoop-yarn-server/hadoop-yarn-server-resourcemanager/src/main/java/org/apache/hadoop/yarn/server/resourcemanager/reservation/RLESparseResourceAllocation.java)。預測的資源需求如下所示,供您參考。
本節將引導您完成資源估計器服務的設定。設定檔位於 $ResourceEstimatorServiceHome/conf/resourceestimator-config.xml。
resourceestimator.solver.lp.alpha資源估計器有一個整合的線性規劃求解器來做出預測(請參閱 https://www.microsoft.com/en-us/research/wp-content/uploads/2016/10/osdi16-final107.pdf 以取得更多詳細資訊),而此參數調整線性規劃模型中資源過度配置和配置不足之間的折衷。此參數範圍從 0 到 1,較大的 alpha 值表示模型可以更好地將過度配置降到最低。預設值為 0.1。
resourceestimator.solver.lp.beta此參數控制線性規劃模型的概化。此參數範圍從 0 到 1。預設值為 0.1。
resourceestimator.solver.lp.minJobRuns為了做出預測而需要的最小工作執行次數。預設值為 2。
resourceestimator.timeInterval用於將工作執行離散化為區間的時間長度。請注意,估計器會針對每個區間做出資源配置預測。較小的時間區間具有較精細的預測粒度,但它也需要較長的時間和較大的空間來進行預測。預設值為 5(秒)。
resourceestimator.skylinestore.providerskylinestore 提供者的類別名稱。預設值為 org.apache.hadoop.resourceestimator.skylinestore.impl.InMemoryStore,這是 skylinestore 的記憶體內實作。如果使用者想要使用自己的 skylinestore 實作,他們需要相應地變更此值。
resourceestimator.translator.provider轉譯器提供者的類別名稱。預設值為 org.apache.hadoop.resourceestimator.translator.impl.BaseLogParser,它從記錄串流中萃取資源 skylines。如果使用者想要使用自己的轉譯器實作,他們需要相應地變更此值。
resourceestimator.translator.line-parser翻譯器單行解析器的類別名稱,用於解析日誌中的單行。預設值為 org.apache.hadoop.resourceestimator.translator.impl.NativeSingleLineParser,它可以解析範例日誌中的單行。請注意,如果使用者想要解析 Hadoop Resource Manager (https://hadoop.dev.org.tw/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html) 日誌,他們需要將值設定為 org.apache.hadoop.resourceestimator.translator.impl.RmSingleLineParser。如果他們想要實作單行解析器來解析其自訂的日誌檔,他們需要相應地變更此值。
resourceestimator.solver.provider求解器提供者的類別名稱。預設值為 org.apache.hadoop.resourceestimator.solver.impl.LpSolver,它會納入線性規劃模型來進行預測。如果使用者想要實作自己的模型,他們需要相應地變更此值。
resourceestimator.service-portResourceEstimatorService 偵聽的埠。預設值為 9998。
對於 SkylineStore,我們計畫提供持續性儲存實作。我們正在考慮 HBase 以確保我們未來的規模需求。
對於 Translator 模組,我們想要支援 Timeline Service v2 作為主要來源,因為我們想要依賴穩定的 API,而日誌充其量只是不穩定的。
工作資源需求可能會因偏斜、競爭、輸入資料或程式碼變更等因素而因執行而異。我們想要設計一個 Reprovisioner 模組,它會在執行時動態監控工作進度,如果進度比預期慢,則會找出效能瓶頸,並使用 ReservationUpdateRequest 相應地動態調整工作的資源配置。
當 Estimator 預測工作的資源需求時,我們想要根據估計誤差(過度配置和配置不足的組合)等提供與預測相關的信心水準。
對於 Estimator 模組,我們可以整合機器學習工具(例如強化學習)以進行更好的預測。我們也可以與特定領域的求解器(例如 PerfOrator)整合以提升預測品質。
對於 Estimator 模組,我們想要設計增量求解器,它只能根據新的日誌增量更新工作的資源需求。