
Dynamometer 是一個用於執行 Hadoop 的 HDFS NameNode 效能測試的工具。目的是透過根據生產檔案系統映像初始化 NameNode,並根據透過 NameNode 的稽核記錄等方式收集的生產工作負載進行重播,提供真實的環境。這允許重播的工作負載不僅在特性上與生產環境中體驗到的類似,而且實際上是相同的。
Dynamometer 會啟動一個 YARN 應用程式,該應用程式會啟動一個 NameNode 和可組態數量的 DataNode,並將整個 HDFS 群集模擬為單一應用程式。有一個額外的 workload 工作會作為 MapReduce 工作執行,它接受稽核記錄作為輸入,並使用其中包含的資訊向 NameNode 提交相符的請求,對服務造成負載。
Dynamometer 可以針對不同的 Hadoop 版本或不同的組態執行相同的負載,允許測試組態調整和程式碼變更,而無需部署到真正的超大規模群集。
在整個文件中,我們將使用「Dyno-HDFS」、「Dyno-NN」和「Dyno-DN」來指稱在 Dynamometer 應用程式內部啟動的 HDFS 群集、NameNode 和 DataNode(分別)。沒有限定條件地使用 HDFS、YARN 和 NameNode 等術語是指 Dynamometer 在其上執行的現有基礎架構。
有關 Dynamometer 的運作方式(與如何使用不同)的更多詳細資訊,請參閱本頁末端的架構區段。
Dynamometer 是以 YARN 應用程式為基礎,因此執行時需要現有的 YARN 集群。它也需要附帶的 HDFS 執行個體來儲存一些用於通訊的暫時檔案。
Dynamometer 包含三個主要元件,每個元件都在自己的模組中
dynamometer-infra):這是啟動 Dyno-HDFS 集群的 YARN 應用程式。dynamometer-workload):這是重播稽核記錄的 MapReduce 作業。dynamometer-blockgen):這是用於為每個 Dyno-DN 產生輸入檔案的 MapReduce 作業;其執行是執行基礎架構應用程式的先決步驟。所有這些元件的已編譯版本都將包含在標準 Hadoop 發行版中。您可以在 share/hadoop/tools/dynamometer 中的封裝發行版中找到它們。
在啟動 Dynamometer 應用程式之前,必須完成許多設定步驟,指示 Dynamometer 要使用的組態、要使用的版本、載入時要使用的 fsimage 等。這些步驟可以執行一次,將所有內容就定位,然後可以針對它們執行許多 Dynamometer 執行,並進行微調以測量變異。
下面討論的指令碼可以在發行版的 share/hadoop/tools/dynamometer/dynamometer-{infra,workload,blockgen}/bin 目錄中找到。對應的 Java JAR 檔案可以在 share/hadoop/tools/lib/ 目錄中找到。以下對 bin 檔案的參考假設目前的作業目錄是 share/hadoop/tools/dynamometer。
在啟動您的第一個 Dyno-HDFS 集群之前,需要執行許多步驟
從您的 NameNode 收集 fsimage 和相關檔案。這將包括 NameNode 在檢查點過程中建立的 fsimage_TXID 檔案、包含映像的 md5 hash 的 fsimage_TXID.md5、包含一些元資料的 VERSION 檔案,以及可以使用離線映像檢視器從 fsimage 產生的 fsimage_TXID.xml 檔案
hdfs oiv -i fsimage_TXID -o fsimage_TXID.xml -p XML
如果您有備用/待命 NameNode,建議您從中收集這些檔案,以避免對您的活動 NameNode 造成額外負載。
所有這些檔案都必須放置在 HDFS 上的某個位置,各種工作才能存取它們。它們都應該放在同一個資料夾中,例如 hdfs:///dyno/fsimage。
所有這些步驟都可以使用 upload-fsimage.sh 程式碼自動執行,例如。
./dynamometer-infra/bin/upload-fsimage.sh 0001 hdfs:///dyno/fsimage
其中 0001 是所需 fsimage 的交易 ID。有關更多詳細資訊,請參閱腳本的使用資訊。
收集 Hadoop Distribution Tarball,用於啟動 Dyno-NN 和 -DN。例如,如果要針對 Hadoop 3.0.2 進行測試,請使用 hadoop-3.0.2.tar.gz。此 Distribution 包含 Dynamometer 不需要的幾個元件(例如 YARN),因此為了縮小其大小,您可以選擇使用 create-slim-hadoop-tar.sh 程式碼
./dynamometer-infra/bin/create-slim-hadoop-tar.sh hadoop-VERSION.tar.gz
Hadoop tar 可以存在於 HDFS 上,或存在於客戶端將從其執行的本地端。其路徑將透過 -hadoop_binary_path 參數提供給客戶端。
或者,如果您使用 -hadoop_version 參數,您可以簡單地指定您想要針對哪個版本執行(例如「3.0.2」),客戶端將嘗試從 Apache 鏡像自動下載它。有關更多詳細資訊,請參閱客戶端的使用資訊。
準備組態目錄。您需要使用標準 Hadoop 組態配置指定組態目錄,例如它應該包含 etc/hadoop/*-site.xml。這決定了 Dyno-NN 和 -DN 將使用什麼組態啟動。必須修改才能使 Dynamometer 正常運作的組態(例如 fs.defaultFS 或 dfs.namenode.name.dir)將在執行時覆寫。如果在本地端可用,這可以是一個目錄,否則可以是本地端或遠端(HDFS)儲存裝置上的歸檔檔。
這將使用 fsimage_TXID.xml 檔案產生區塊清單,每個 Dyno-DN 都應該向 Dyno-NN 宣告這些區塊。它以 MapReduce 工作執行。
./dynamometer-blockgen/bin/generate-block-lists.sh
-fsimage_input_path hdfs:///dyno/fsimage/fsimage_TXID.xml
-block_image_output_dir hdfs:///dyno/blocks
-num_reducers R
-num_datanodes D
在此範例中,上傳的 XML 檔案用於將區塊清單產生到 hdfs:///dyno/blocks。工作使用 R 個 Reducer,並產生 D 個區塊清單 - 這將決定 Dyno-HDFS 群集中啟動多少個 Dyno-DN。
如果您打算使用 Dynamometer 的稽核追蹤重播功能,此步驟才需要;如果您只是打算啟動 Dyno-HDFS 群集,您可以跳到下一章節。
稽核追蹤重播接受每個 Mapper 一個輸入檔,目前支援兩種輸入格式,可透過 auditreplay.command-parser.class 組態進行設定。將自動為啟動時指定的稽核記錄目錄中的每個稽核記錄檔建立一個 Mapper。
預設值是直接格式,org.apache.hadoop.tools.dynamometer.workloadgenerator.audit.AuditLogDirectParser。這接受標準組態稽核記錄器產生的格式中的檔案,例如以下列行:
1970-01-01 00:00:42,000 INFO FSNamesystem.audit: allowed=true ugi=hdfs ip=/127.0.0.1 cmd=open src=/tmp/foo dst=null perm=null proto=rpc
使用此格式時,您還必須指定 auditreplay.log-start-time.ms,它應該是稽核追蹤的開始時間(自 Unix 紀元以來的毫秒數)。所有對應器都需要同意單一開始時間。例如,如果上述行是第一個稽核事件,您會指定 auditreplay.log-start-time.ms=42000。在一個檔案中,稽核記錄必須按照時間戳遞增順序排列。
另一個受支援的格式是 org.apache.hadoop.tools.dynamometer.workloadgenerator.audit.AuditLogHiveTableParser。它接受 Hive 查詢產生的檔案,其輸出欄位依序為
relativeTimestamp:事件時間偏移量(以毫秒為單位),從追蹤開始算起ugi:提交使用者的使用者資訊command:命令名稱,例如「開啟」source:來源路徑dest:目的地路徑sourceIP:事件的來源 IP假設您的稽核記錄在 Hive 中可用,這可以透過類似下列的 Hive 查詢產生
INSERT OVERWRITE DIRECTORY '${outputPath}'
SELECT (timestamp - ${startTimestamp} AS relativeTimestamp, ugi, command, source, dest, sourceIP
FROM '${auditLogTableLocation}'
WHERE timestamp >= ${startTimestamp} AND timestamp < ${endTimestamp}
DISTRIBUTE BY src
SORT BY relativeTimestamp ASC;
您可能會注意到,在上面顯示的 Hive 查詢中,有一個 DISTRIBUTE BY src 子句,表示輸出檔案應該由呼叫者的來源 IP 分割。這樣做是為了嘗試維護來自單一客戶端的請求更接近的順序。Dynamometer 不保證嚴格的運作順序,即使在分割區中也是如此,但順序通常會在分割區內比跨分割區更緊密地維護。
無論您使用 Hive 或原始稽核記錄,都必須根據工作負載重播所需的同時客戶端數量分割稽核記錄。使用來源 IP 作為分割金鑰是一種方法,具有上述討論的潛在優點,但任何分割方案都應該運作得相當好。
完成上述設定步驟後,您就可以啟動 Dyno-HDFS 群集並針對它重播一些工作負載了!
啟動 Dyno-HDFS YARN 應用程式的客戶端可以在 Dyno-HDFS 群集完全啟動後選擇啟動工作負載重播工作。這會讓每次重播成為客戶端的單一執行,讓各種組態的測試變得容易。您也可以分開啟動這兩個,以獲得更多控制權。同樣地,可以為 Dynamometer/YARN 未控制的外部 NameNode 啟動 Dyno-DN。這對於測試尚未受支援的 NameNode 組態(例如 HA NameNode)很有用。您可以透過將 -namenode_servicerpc_addr 參數傳遞給基礎架構應用程式,並將值指向外部 NameNode 的服務 RPC 位址來執行此操作。
首先啟動基礎架構應用程式以開始啟動內部 HDFS 群集,例如
./dynamometer-infra/bin/start-dynamometer-cluster.sh
-hadoop_binary_path hadoop-3.0.2.tar.gz
-conf_path my-hadoop-conf
-fs_image_dir hdfs:///fsimage
-block_list_path hdfs:///dyno/blocks
這示範了必要的參數。您可以使用 -help 旗標執行此操作,以查看進一步的使用資訊。
客戶端會追蹤 Dyno-NN 的啟動進度,以及它認為有多少個 Dyno-DN 是運作中的。當 Dyno-NN 退出安全模式並準備好使用時,它會透過記錄通知。
此時,可以啟動工作負載工作(僅對應的 MapReduce 工作),例如
./dynamometer-workload/bin/start-workload.sh
-Dauditreplay.input-path=hdfs:///dyno/audit_logs/
-Dauditreplay.output-path=hdfs:///dyno/results/
-Dauditreplay.num-threads=50
-nn_uri hdfs://namenode_address:port/
-start_time_offset 5m
-mapper_class_name AuditReplayMapper
工作負載產生的類型是可以設定的;AuditReplayMapper 重新播放先前討論過的稽核記錄追蹤。AuditReplayMapper 是透過設定來設定;需要 auditreplay.input-path、auditreplay.output-path 和 auditreplay.num-threads 來指定稽核記錄檔案的輸入路徑、結果的輸出路徑以及每個對應工作任務的執行緒數目。會啟動等於 input-path 中檔案數目的對應工作任務;每個工作任務會讀取其中一個輸入檔案,並使用 num-threads 執行緒來重新播放該檔案中包含的事件。會盡力以與其最初發生的相同速度忠實地重新播放稽核記錄事件(選擇性地,這可透過指定 auditreplay.rate-factor 來調整,此為重新播放速率的乘法因子,例如使用 2.0 以兩倍原始速度重新播放事件)。
AuditReplayMapper 會以 CSV 格式將基準測試結果輸出到輸出目錄中的檔案 part-r-00000。每行格式為 user,type,operation,numops,cumulativelatency,例如 hdfs,WRITE,MKDIRS,2,150。
若要讓基礎架構應用程式用戶端自動啟動工作負載,工作負載工作的工作參數會傳遞給基礎架構指令碼。目前僅支援 AuditReplayMapper 以這種方式執行。若要啟動與上述相同的參數的整合應用程式,可以使用下列內容
./dynamometer-infra/bin/start-dynamometer-cluster.sh
-hadoop_binary hadoop-3.0.2.tar.gz
-conf_path my-hadoop-conf
-fs_image_dir hdfs:///fsimage
-block_list_path hdfs:///dyno/blocks
-workload_replay_enable
-workload_input_path hdfs:///dyno/audit_logs/
-workload_output_path hdfs:///dyno/results/
-workload_threads_per_mapper 50
-workload_start_delay 5m
以這種方式執行時,用戶端會在工作負載完成後自動處理關閉 Dyno-HDFS 集群。若要查看支援參數的完整清單,請執行此指令,並加上 -help 旗標。
Dynamometer 是實作於 YARN 上方的應用程式。Dynamometer 應用程式中有三個主要參與者
驅動程式中封裝的邏輯使用戶能夠使用單一指令執行 Dynamometer 的完整測試執行,這使得能夠執行諸如掃描不同參數以找出最佳設定等工作。
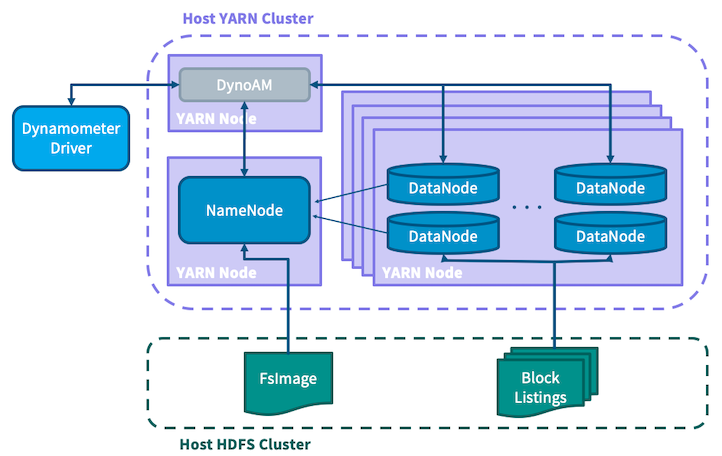
基礎架構應用程式撰寫為原生 YARN 應用程式,其中會啟動一個 NameNode 和多個 DataNode,並將它們連接在一起,以建立一個完全模擬的 HDFS 集群。為了讓 Dynamometer 提供極為逼真的場景,必須有一個集群,從 NameNode 的角度來看,包含與生產集群相同資訊。這就是為什麼上述設定步驟會先從生產 NameNode 收集 FsImage 檔案,並將其放置在主機 HDFS 集群上的原因。為了避免必須複製整個集群的區塊,Dynamometer 充分利用了以下事實:儲存在區塊中的實際資料與 NameNode 無關,NameNode 僅知道區塊的元資料。Dynamometer 的 blockgen 工作首先使用離線影像檢視器將 FsImage 轉換為 XML,然後分析此 XML 以擷取每個區塊的元資料,接著分割此資訊,然後將其放置在 HDFS 上,供模擬的 DataNode 使用。SimulatedFSDataset 用於繞過 DataNode 儲存層,並僅儲存從前一階段擷取的資訊載入的區塊元資料。此架構允許 Dynamometer 將許多模擬的 DataNode 封裝到每個實體節點上,因為元資料的大小比資料本身小好幾個數量級。
為了建立與生產環境相符的壓力測試,Dynamometer 需要一種方法來收集有關生產工作負載的資訊。為此,會使用 HDFS 稽核記錄,其中包含針對 NameNode 的所有面向客戶端操作的忠實記錄。透過重播此稽核記錄來重新建立客戶端負載,並執行模擬的 DataNode 來重新建立集群管理負載,Dynamometer 能夠提供生產 NameNode 條件的逼真模擬。
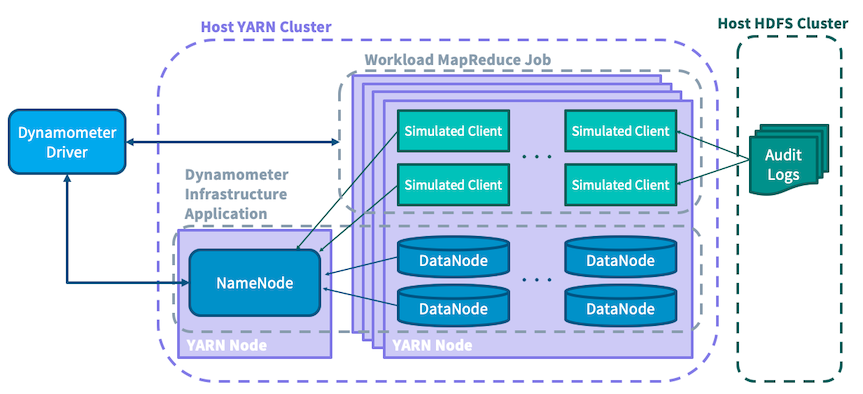
負載很重的 NameNode 每秒可以服務數萬個操作;為了引發此類負載,Dynamometer 需要許多客戶端提交要求。為了確保每個要求都有與其原始提交相同的效應和效能影響,Dynamometer 會嘗試以保留其原始順序的方式提出相關要求(例如,建立目錄後列出該目錄)。出於此原因,建議按來源 IP 位址分割稽核記錄檔案,並假設來自同一主機的要求比來自不同主機的要求有更緊密的因果關係。為了簡化起見,壓力測試工作撰寫為僅限對應的 MapReduce 工作,其中每個對應器都會使用分割的稽核記錄檔案,並針對模擬的 NameNode 重播其中包含的命令。在執行期間,會收集有關重播的統計資料,例如不同類型要求的延遲時間。
若要查看更多有關 Dynamometer 的資訊,您可以參閱 宣佈其最初發行的部落格文章 或 此簡報。