
檢視檔案系統 (ViewFs) 提供一種管理多個 Hadoop 檔案系統命名空間 (或命名空間磁碟區) 的方法。它特別適用於在 HDFS 聯盟 中具有多個名稱節點,因此有多個命名空間的叢集。ViewFs 類似於某些 Unix/Linux 系統中的「用戶端側掛載表格」。ViewFs 可用於建立個人化命名空間檢視,以及每個叢集的共用檢視。
本指南是在具有多個叢集的 Hadoop 系統背景下提出的,每個叢集都可能聯盟到多個命名空間。它還說明如何在聯盟式 HDFS 中使用 ViewFs,以提供每個叢集的全球命名空間,讓應用程式能夠以類似於聯盟前世界的方式運作。
在 HDFS 聯盟 之前的舊世界中,叢集有一個單一名稱節點,為該叢集提供單一檔案系統命名空間。假設有多個叢集。每個叢集的檔案系統命名空間完全獨立且不相交。此外,實體儲存不會跨叢集共用 (即資料節點不會跨叢集共用)。
每個叢集的 core-site.xml 都有一個設定檔屬性,將預設檔案系統設定為該叢集的名稱節點
<property> <name>fs.default.name</name> <value>hdfs://namenodeOfClusterX:port</value> </property>
此類設定檔屬性允許使用斜線相對名稱來解析相對於叢集名稱節點的路徑。例如,使用上述設定檔,路徑 /foo/bar 指的是 hdfs://namenodeOfClusterX:port/foo/bar。
此設定檔屬性會設定在叢集上的每個閘道,以及該叢集的主要服務上,例如 JobTracker 和 Oozie。
因此,在 core-site.xml 如上所述設定的叢集 X 上,典型路徑名稱為
/foo/bar
hdfs://namenodeOfClusterX:port/foo/bar,如同先前所述。hdfs://namenodeOfClusterX:port/foo/bar
/foo/bar,因為它允許在需要時將應用程式及其資料透明地移至另一個叢集。hdfs://namenodeOfClusterY:port/foo/bar
distcp hdfs://namenodeClusterY:port/pathSrc hdfs://namenodeClusterZ:port/pathDest
webhdfs://namenodeClusterX:http_port/foo/bar
http://namenodeClusterX:http_port/webhdfs/v1/foo/bar 和 http://proxyClusterX:http_port/foo/bar
當使用者在叢集中時,建議使用類型 (1) 的路徑名稱,而不是類型 (2) 的完整 URI。完整 URI 類似於位址,不允許應用程式與其資料一起移動。
假設有多個叢集。每個叢集有一個或多個名稱節點。每個名稱節點都有自己的命名空間。名稱節點只屬於一個叢集。同一個叢集中的名稱節點共用該叢集的實體儲存空間。叢集之間的命名空間仍然是獨立的。
作業會根據儲存需求,決定每個叢集中的名稱節點儲存哪些內容。例如,他們可能會將所有使用者資料 (/user/<username>) 放在一個名稱節點中,將所有饋送資料 (/data) 放在另一個名稱節點中,將所有專案 (/projects) 放在另一個名稱節點中,依此類推。
為了提供與舊世界的透明度,ViewFs 檔案系統 (即用戶端安裝表格) 會用於為每個叢集建立獨立的叢集命名空間檢視,這類似於舊世界的命名空間。用戶端安裝表格類似於 Unix 安裝表格,而且它們會使用舊的命名慣例安裝新的命名空間磁碟區。下圖顯示安裝表格安裝四個命名空間磁碟區 /user、/data、/projects 和 /tmp
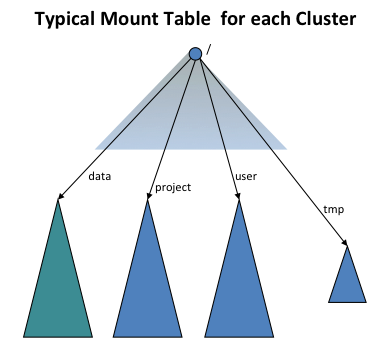
ViewFs 實作 Hadoop 檔案系統介面,就像 HDFS 和本機檔案系統一樣。它是一個瑣碎的檔案系統,因為它只允許連結到其他檔案系統。由於 ViewFs 實作 Hadoop 檔案系統介面,因此它可以透明地使用 Hadoop 工具。例如,所有 shell 指令都可以與 ViewFs 一起使用,就像與 HDFS 和本機檔案系統一起使用一樣。
在每個叢集的設定中,預設檔案系統會設定為該叢集的安裝表格,如下所示 (將其與 單一名稱節點叢集 中的設定進行比較)。
<property> <name>fs.defaultFS</name> <value>viewfs://clusterX</value> </property>
URI 中 viewfs:// 範例後的授權是掛載表格名稱。建議叢集的掛載表格應以叢集名稱命名。然後 Hadoop 系統會在 Hadoop 組態檔案中尋找名稱為「clusterX」的掛載表格。作業會安排所有閘道和服務機器包含所有叢集的掛載表格,以便針對每個叢集,將預設檔案系統設定為如上所述的該叢集的 ViewFs 掛載表格。
掛載表格的掛載點會在標準 Hadoop 組態檔案中指定。viewfs 的所有掛載表格組態項目都以 fs.viewfs.mounttable. 為字首。連結其他檔案系統的掛載點會使用 link 標籤指定。建議掛載點名稱與連結的檔案系統目標位置相同。對於掛載表格中未組態的所有命名空間,我們可以透過 linkFallback 將它們備份至預設檔案系統。
在以下掛載表格組態中,命名空間 /data 連結至檔案系統 hdfs://nn1-clusterx.example.com:8020/data,/project 連結至檔案系統 hdfs://nn2-clusterx.example.com:8020/project。掛載表格中未組態的所有命名空間(例如 /logs)都連結至檔案系統 hdfs://nn5-clusterx.example.com:8020/home。
<configuration>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./data</name>
<value>hdfs://nn1-clusterx.example.com:8020/data</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./project</name>
<value>hdfs://nn2-clusterx.example.com:8020/project</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./user</name>
<value>hdfs://nn3-clusterx.example.com:8020/user</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./tmp</name>
<value>hdfs://nn4-clusterx.example.com:8020/tmp</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.linkFallback</name>
<value>hdfs://nn5-clusterx.example.com:8020/home</value>
</property>
</configuration>
或者,我們可以透過 linkMergeSlash 將掛載表格的根目錄與另一個檔案系統的根目錄合併。在以下掛載表格組態中,叢集 Y 的根目錄與 hdfs://nn1-clustery.example.com:8020 的根目錄檔案系統合併。
<configuration>
<property>
<name>fs.viewfs.mounttable.ClusterY.linkMergeSlash</name>
<value>hdfs://nn1-clustery.example.com:8020/</value>
</property>
</configuration>
因此,在叢集 X(其中 core-site.xml 設定為讓預設檔案系統使用該叢集的掛載表格)中,典型的路徑名稱為
/foo/bar
viewfs://clusterX/foo/bar。如果在舊的非聯合環境中使用此類路徑名稱,則轉換至聯合環境會很透明。viewfs://clusterX/foo/bar
/foo/bar,因為它允許在需要時將應用程式及其資料透明地移至另一個叢集。viewfs://clusterY/foo/bar
distcp viewfs://clusterY/pathSrc viewfs://clusterZ/pathDest
viewfs://clusterX-webhdfs/foo/bar
http://namenodeClusterX:http_port/webhdfs/v1/foo/bar 和 http://proxyClusterX:http_port/foo/bar
當在叢集內部時,建議使用類型 (1) 的路徑名稱,而不是像 (2) 那樣的完全限定 URI。此外,應用程式不應使用掛載點的知識,也不應使用類似於 hdfs://namenodeContainingUserDirs:port/joe/foo/bar 的路徑來參考特定名稱節點中的檔案。您應該使用 /user/joe/foo/bar 來代替。
請回想一下,在舊世界中無法跨名稱節點或叢集重新命名檔案或目錄。在新世界中也是如此,但有額外的變化。例如,在舊世界中,可以執行以下命令。
rename /user/joe/myStuff /data/foo/bar
如果 /user 和 /data 實際上儲存在叢集內不同名稱節點上,則這在新的世界中將無法執行。
HDFS 和其他分散式檔案系統透過某種形式的備援提供資料復原能力,例如區塊複製或更精密的分布式編碼。但是,現代設定可能包含多個 Hadoop 叢集、企業檔案伺服器,並在內部和外部託管。Nfly 掛載點使單一邏輯檔案可以由多個檔案系統同步複製。它設計用於最大 1 GB 的相對較小檔案。一般來說,這是單一核心/單一網路連結效能的函數,因為邏輯存在於使用 ViewFs 的單一用戶端 JVM 中,例如 FsShell 或 MapReduce 任務。
考慮以下範例,以了解 Nfly 的基本設定。假設我們想要讓目錄 ads 在由 URI 表示的三個檔案系統上複製:uri1、uri2 和 uri3。
<property>
<name>fs.viewfs.mounttable.global.linkNfly../ads</name>
<value>uri1,uri2,uri3</value>
</property>
請注意屬性名稱中有 2 個連續的 ..。它們是因為掛載點的高階調整的設定為空,我們將在後續章節中說明。屬性值是 URI 的逗號分隔清單。
URI 可以指向不同區域的不同叢集 hdfs://datacenter-east/ads、s3a://models-us-west/ads、hdfs://datacenter-west/ads,或者在最簡單的情況下指向相同檔案系統下的不同目錄,例如 file:/tmp/ads1、file:/tmp/ads2、file:/tmp/ads3
在全域路徑 viewfs://global/ads 下執行的所有修改,如果底層系統可用,將傳播至所有目的地 URI。
例如,如果我們透過 Hadoop shell 建立一個檔案
hadoop fs -touchz viewfs://global/ads/z1
我們將在後續設定中透過本機檔案系統找到它
ls -al /tmp/ads*/z1 -rw-r--r-- 1 user wheel 0 Mar 11 12:17 /tmp/ads1/z1 -rw-r--r-- 1 user wheel 0 Mar 11 12:17 /tmp/ads2/z1 -rw-r--r-- 1 user wheel 0 Mar 11 12:17 /tmp/ads3/z1
從全域路徑讀取的資料會由第一個不會導致例外狀況的檔案系統處理。存取檔案系統的順序取決於它們是否在此刻可用,以及是否存在拓撲順序。
掛載點 linkNfly 可以進一步使用以逗號分隔的 key=value 成對參數清單傳遞的參數進行設定。目前支援下列參數。
minReplication=int 決定必須處理寫入修改且不產生例外的目的地數量下限,如果低於 nfly 寫入會失敗。將 minReplication 設定為高於目標 URI 數量是設定錯誤。預設值為 2。
如果 minReplication 低於目標 URI 數量,我們可能會有一些目標 URI 沒有最新的寫入。這可以用下列設定控制的更昂貴的讀取作業來彌補
readMostRecent=boolean 如果設定為 true,會導致 Nfly 客戶端檢查所有目標 URI 下的路徑,而不仅仅是基於拓撲順序的第一個。在目前所有可用的路徑中,會處理修改時間最晚的那個。
repairOnRead=boolean 如果設定為 true,會導致 Nfly 將最新的複本複製到過期的目標,以便後續讀取可以再次從最近的複本便宜地完成。
Nfly 尋求從「最近」的目標 URI 滿足讀取。
為此,Nfly 將機架感知的概念延伸至目標 URI 的授權。
Nfly 套用網路拓撲來解析 URI 的授權。在異質設定中,最常使用基於指令碼的對應。我們可以有一個提供下列拓撲對應的指令碼
| URI | 拓撲 |
|---|---|
hdfs://datacenter-east/ads |
/us-east/onpremise-hdfs |
s3a://models-us-west/ads |
/us-west/aws |
hdfs://datacenter-west/ads |
/us-west/onpremise-hdfs |
如果目標 URI 沒有授權部分,例如 file:/,Nfly 會注入客戶端的本機節點名稱。
<property>
<name>fs.viewfs.mounttable.global.linkNfly.minReplication=3,readMostRecent=true,repairOnRead=false./ads</name>
<value>hdfs://datacenter-east/ads,hdfs://datacenter-west/ads,s3a://models-us-west/ads,file:/tmp/ads</value>
</property>
FileSystem fs = FileSystem.get("viewfs://global/", ...);
FSDataOutputStream out = fs.create("viewfs://global/ads/f1");
out.write(...);
out.close();
上述程式碼將導致下列執行。
在每個目標 URI 下建立一個不可見檔案 _nfly_tmp_f1,例如 hdfs://datacenter-east/ads/_nfly_tmp_f1、hdfs://datacenter-west/ads/_nfly_tmp_f1 等。這會透過呼叫底層檔案系統上的 create 來完成,並傳回一個包裝所有四個輸出串流的 FSDataOutputStream 物件 out。
因此,對 out 的每個後續寫入都可以轉發到每個包裝的串流。
在 out.close 中,所有串流都會關閉,且檔案會從 _nfly_tmp_f1 變更名稱為 f1。所有檔案都會接收與此步驟開始時之客戶端系統時間對應的相同修改時間。
如果至少有 minReplication 個目的地已完成步驟 1-3 且未發生任何失敗,Nfly 會將交易視為邏輯上已提交;否則,它會盡力嘗試清除暫時檔案。
請注意,由於 4 是盡力步驟,且客戶端 JVM 可能會發生故障且無法繼續作業,因此建議提供某種 cron 作業來清除此類 _nfly_tmp 檔案。
當我從非聯合世界轉移到聯合世界時,我必須追蹤不同磁碟區的名稱節點;我該如何執行此動作?
不需要。請參閱上述範例 – 您正在使用相對名稱並利用預設檔案系統,或將路徑從 hdfs://namenodeCLusterX/foo/bar 變更為 viewfs://clusterX/foo/bar。
如果作業將一些檔案從一個名稱節點移至叢集內另一個名稱節點,會發生什麼事?
作業可能會將檔案從一個名稱節點移至另一個名稱節點,以處理儲存容量問題。他們會以避免應用程式中斷的方式執行此動作。讓我們舉幾個範例。
範例 1:/user 和 /data 位於一個名稱節點上,但稍後它們需要位於不同的名稱節點上,以處理容量問題。確實,作業會為 /user 和 /data 建立個別的掛載點。在變更之前,/user 和 /data 的掛載會指向同一個名稱節點,例如 namenodeContainingUserAndData。作業會更新掛載表格,以便將掛載點分別變更為 namenodeContaingUser 和 namenodeContainingData。
範例 2:所有專案都安裝在一個名稱節點上,但稍後它們需要兩個或更多個名稱節點。ViewFs 允許掛載,例如 /project/foo 和 /project/bar。這允許更新掛載表格,以指向對應的名稱節點。
每個 core-site.xml 中的掛載表格或在它自己的個別檔案中?
計畫是將掛載表格保留在個別檔案中,並讓 core-site.xml xincluding 它。雖然可以在每個機器上保留這些檔案,但最好使用 HTTP 從中央位置存取它。
組態是否應僅包含一個叢集或所有叢集的掛載表格定義?
組態應包含所有叢集的掛載定義,因為需要存取其他叢集中的資料,例如使用 distcp。
由於作業可能會隨著時間變更掛載表格,因此實際上何時讀取掛載表格?
當作業提交至叢集時,會讀取掛載表格。core-site.xml 中的 XInclude 會在作業提交時間擴充。這表示如果變更掛載表格,則需要重新提交作業。由於這個原因,我們希望實作合併掛載,這將大幅減少變更掛載表格的需求。此外,我們希望透過另一種機制讀取掛載表格,該機制會在未來作業開始時間初始化。
JobTracker(或 Yarn 的資源管理員)本身會使用 ViewFs 嗎?
不,不需要。NodeManager 也不需要。
ViewFs 是否僅允許在頂層掛載?
不,它更通用。例如,可以掛載 /user/joe 和 /user/jane。在這種情況下,會在掛載表中為 /user 建立一個內部唯讀目錄。對 /user 的所有操作都是有效的,但 /user 是唯讀的。
一個應用程式跨群集工作,需要持續儲存檔案路徑。它應該儲存哪些路徑?
您應該儲存 viewfs://cluster/path 類型的路徑名稱,這與執行應用程式時使用的路徑名稱相同。只要操作以透明的方式移動資料,這就能讓您免受群集內名稱節點中資料移動的影響。如果資料從一個群集移動到另一個群集,它無法保護您;舊的(聯邦化之前的)世界也無法保護您免受群集之間的此類資料移動影響。
委派權杖呢?
您提交作業的群集(包括該群集掛載表的掛載磁碟)以及您的 MapReduce 作業的輸入和輸出路徑(包括透過指定輸入和輸出路徑的掛載表掛載的所有磁碟)的委派權杖都會自動處理。此外,還有一種方法可以將其他委派權杖新增到基本群集組態中以應付特殊情況。
請參閱 View 檔案系統過載方案指南
View 檔案系統掛載點是基於鍵值對的對應系統。對於可以將對應組態抽象為規則的使用者案例,它並不友善。例如,使用者想要為每個使用者提供一個 GCS 儲存空間,而總共有數千個使用者。基於舊鍵值對的方法無法順利運作,原因有以下幾個
掛載表由檔案系統用戶端使用。將組態傳播到所有用戶端需要成本,如果可能,我們應該避免這樣做。View 檔案系統過載方案指南可以透過集中式掛載表管理來協助分發。但掛載表在每次變更時仍必須更新。如果提供基於規則的掛載表,則可以大幅避免變更。
用戶端必須了解掛載表中的所有鍵值對。當可掛載項目增加到數千個時,這並非理想情況。例如,即使使用者只需要一個,也可能會初始化數千個檔案系統。而且組態本身在擴充時會變得過於龐大。
在基於金鑰值對的掛載表中,檢視檔案系統會將每個掛載點視為一個分割區。有幾個檔案系統 API 會導致對所有分割區執行操作。例如,有一個具有多個掛載的 HDFS 群集。使用者想要執行「hadoop fs -put file viewfs://hdfs.namenode.apache.org/tmp/” cmd」來將資料從本機磁碟複製到我們的 HDFS 群集。此 cmd 會觸發 ViewFileSystem 呼叫 setVerifyChecksum() 方法,這會初始化每個掛載點的檔案系統。對於基於正規表示式規則的掛載表項目,我們在解析之前無法知道對應路徑。因此,在這種情況下,基於正規表示式的掛載表項目將被忽略。檔案系統 (ChRootedFileSystem) 會在存取時建立。但基礎檔案系統會快取在 ViewFileSystem 的內部快取中。
<property>
<name>fs.viewfs.rename.strategy</name>
<value>SAME_FILESYSTEM_ACROSS_MOUNTPOINT</value>
</property>
以下是基本正規表示式掛載點設定範例。${username} 是 Java 正規表示式中的命名擷取群組。
<property>
<name>fs.viewfs.mounttable.hadoop-nn.linkRegx./^(?<username>\\w+)</name>
<value>gs://${username}.hadoop.apache.org/</value>
</property>
解析範例。
viewfs://hadoop-nn/user1/dir1 => gs://user1.hadoop.apache.org/dir1 viewfs://hadoop-nn/user2 => gs://user2.hadoop.apache.org/
src/key 的格式為
fs.viewfs.mounttable.${VIEWNAME}.linkRegx.${REGEX_STR}
攔截器是一種機制,用於在解析過程中修改來源或目標。它是選用的,可用於滿足使用者案例,例如取代特定字元或取代某些字詞。攔截器只會對正規表示式掛載點運作。RegexMountPointResolvedDstPathReplaceInterceptor 現在是唯一內建的攔截器。
以下是設定 RegexMountPointResolvedDstPathReplaceInterceptor 的正規表示式掛載點項目範例。
<property>
<name>fs.viewfs.mounttable.hadoop-nn.linkRegx.replaceresolveddstpath:_:-#./^(?<username>\\w+)</name>
<value>gs://${username}.hadoop.apache.org/</value>
</property>
replaceresolveddstpath:_:- 是攔截器設定。「replaceresolveddstpath」是攔截器類型,「_」是要取代的字串,「-」是取代後的字串。
解析範例。
viewfs://hadoop-nn/user_ad/dir1 => gs://user-ad.hadoop.apache.org/dir1 viewfs://hadoop-nn/user_ad_click => gs://user-ad-click.hadoop.apache.org/
src/key 的格式為
fs.viewfs.mounttable.${VIEWNAME}.linkRegx.${REGEX_STR}
fs.viewfs.mounttable.${VIEWNAME}.linkRegx.${interceptorSettings}#.${srcRegex}
一般來說,使用者不需要定義掛載表或 core-site.xml 來使用掛載表。這是由作業完成的,正確的設定會設定在正確的閘道機器上,就像今天對 core-site.xml 所做的那樣。
掛載表可以在 core-site.xml 中描述,但最好在 core-site.xml 中使用間接參照來參考個別設定檔,例如 mountTable.xml。將下列設定元素新增到 core-site.xml 以參照 mountTable.xml
<configuration xmlns:xi="http://www.w3.org/2001/XInclude"> <xi:include href="mountTable.xml" /> </configuration>
在檔案 mountTable.xml 中,有一個掛載表「ClusterX」的定義,用於由三個名稱節點管理的三個命名空間磁碟區的假設群集
這裡的 /home 和 /tmp 在由名稱節點 nn1-clusterx.example.com:8020 管理的命名空間中,而專案 /foo 和 /bar 則託管在聯合群集的其他名稱節點上。主目錄基本路徑設定為 /home,以便每個使用者可以使用 FileSystem/FileContext 中定義的 getHomeDirectory() 方法存取其主目錄。
<configuration>
<property>
<name>fs.viewfs.mounttable.ClusterX.homedir</name>
<value>/home</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./home</name>
<value>hdfs://nn1-clusterx.example.com:8020/home</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./tmp</name>
<value>hdfs://nn1-clusterx.example.com:8020/tmp</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./projects/foo</name>
<value>hdfs://nn2-clusterx.example.com:8020/projects/foo</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./projects/bar</name>
<value>hdfs://nn3-clusterx.example.com:8020/projects/bar</value>
</property>
</configuration>