
本文件說明如何設定和管理 Hadoop 的公平呼叫佇列。
請確定 Hadoop 已正確安裝、設定和設定。如需更多資訊,請參閱
Hadoop 伺服器元件,特別是 HDFS NameNode,會從用戶端收到非常大量的 RPC 負載。預設情況下,所有用戶端要求都會透過先進先出佇列路由,並按照到達順序提供服務。這表示單一使用者提交大量要求很容易會讓服務不堪負荷,導致所有其他使用者的服務品質下降。公平呼叫佇列和相關元件的目標是減輕這種影響。
IPC 堆疊中有一些元件具有複雜的交互作用,每個元件都有自己的調整參數。下方的圖片呈現它們交互作用的概略示意圖,以下將說明這些交互作用。
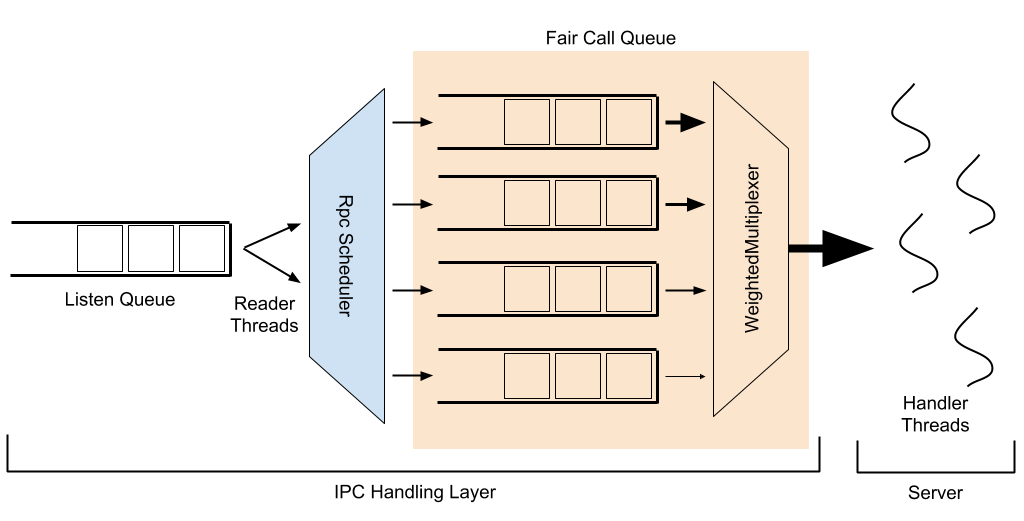
在以下說明中,粗體字詞是指命名實體或可設定項目。
當客戶端向 IPC 伺服器提出要求時,此要求會首先進入監聽佇列。讀取器執行緒會從此佇列中移除要求,並傳遞給可設定的RpcScheduler,以指定優先順序並放入呼叫佇列中;FairCallQueue 作為可插入式實作位於此處(另一種現有實作為 FIFO 佇列)。處理器執行緒會從呼叫佇列中接受要求,處理它們,並回應客戶端。
預設情況下,與 FairCallQueue 一起使用的 RpcScheduler 實作為DecayRpcScheduler,它會維護每個使用者收到的要求計數。此計數會隨著時間衰減;每隔掃描週期(預設為 5 秒),每個使用者的要求數量會乘以衰減因子(預設為 0.5)。這會維持每個使用者的加權/滾動平均要求計數。每次執行掃描時,所有已知使用者的呼叫計數會從最高到最低進行排序。每個使用者會根據來自該使用者的呼叫比例,指定優先順序(預設為 0-3,其中 0 為最高優先順序)。預設優先順序閾值為 (0.125, 0.25, 0.5),表示呼叫超過總數 50% 的使用者(最多只能有一個這樣的使用者)會被置於最低優先順序,呼叫佔總數 25% 到 50% 的使用者會在第二低優先順序,呼叫佔總數 12.5% 到 25% 的使用者會在第二高優先順序,所有其他使用者會被置於最高優先順序。在掃描結束時,每個已知使用者都會有一個快取的優先順序,此優先順序會使用到下一次掃描;在掃描之間出現的新使用者,其優先順序會動態計算。
在 FairCallQueue 中,有多個優先順序佇列,每個佇列都指定一個權重。當要求到達呼叫佇列時,要求會根據呼叫目前指定的優先順序(由 RpcScheduler 指定),放入這些優先順序佇列之一。當處理器執行緒嘗試從呼叫佇列中擷取項目時,它會從哪個佇列擷取會透過RpcMultiplexer 決定;目前這已硬編碼為WeightedRoundRobinMultiplexer。WRRM 會根據佇列的權重提供服務;預設 4 個優先順序層級的預設權重為 (8, 4, 2, 1)。因此,WRRM 會從最高優先順序佇列提供 8 個要求,從第二高優先順序佇列提供 4 個,從第三高優先順序佇列提供 2 個,從最低優先順序佇列提供 1 個,然後再從最高優先順序佇列提供 8 個,以此類推。
除了上述優先權重機制,還有一個可設定的退避機制,其中伺服器會對用戶端傳送例外,而不是處理它;預期用戶端會等待一段時間(例如,透過指數退避)後再重試。通常,當嘗試將要求放入優先佇列(FCQ)中時,如果該佇列已滿,就會觸發退避。這有助於進一步推遲對影響較大的用戶端,減少負載,並可能帶來顯著的效益。還有一個功能,依據回應時間退避,如果較高優先權等級中的要求服務太慢,則較低優先權等級中的要求會退避。例如,如果優先權 1 的回應時間閾值設定為 10 秒,但該佇列中的平均回應時間為 12 秒,則優先權等級 2 或更低的傳入要求會收到退避例外,而優先權等級 0 和 1 的要求會照常進行。目的是在整體系統負載大到足以影響高優先權用戶端時,強制較重的用戶端退避。
上述討論是指要求的使用者,討論如何將要求分組以進行限制。這可透過身分識別提供者設定,預設為UserIdentityProvider。使用者身分識別提供者僅使用提交要求的用戶端使用者名稱。但是,可以使用自訂身分識別提供者,根據其他群組執行限制,或使用外部身分識別提供者。
雖然公平呼叫佇列本身在減輕提交大量要求的使用者影響方面做得很好,但它沒有考慮處理每個要求的成本。因此,在考慮 HDFS NameNode 時,提交 1000 個「getFileInfo」要求的使用者會與在某個非常大的目錄上提交 1000 個「listStatus」要求的使用者優先順序相同,或者提交 1000 個「mkdir」要求的使用者,因為這些要求需要獨佔鎖定名稱系統,因此成本更高。為了在考慮使用者要求的優先順序時考量作業的成本,公平呼叫佇列有一個「基於成本」的延伸,它使用使用者的作業的總處理時間來決定該使用者的優先順序。預設情況下,佇列時間(花費在等待處理的時間)和鎖定等待時間(花費在取得鎖定的時間)不會考慮在成本中,沒有鎖定時花費的處理時間會以中性(1 倍)加權,使用共用鎖定時花費的處理時間會加權 10 倍,使用獨佔鎖定時花費的處理時間會加權 100 倍。這會嘗試根據使用者對伺服器造成的實際負載來設定優先順序。若要啟用此功能,請將 costprovder.impl 設定設定為 org.apache.hadoop.ipc.WeightedTimeCostProvider,如下所述。
本節說明如何設定公平呼叫佇列。
所有呼叫佇列相關設定僅與單一 IPC 伺服器相關。這允許使用單一設定檔來設定不同元件,甚至元件中的不同 IPC 伺服器,以擁有設定獨特的呼叫佇列。每個設定都以 ipc.<port_number> 為前綴,其中 <port_number> 是 IPC 伺服器用於設定的埠。例如,ipc.8020.callqueue.impl 會調整在埠 8020 執行的 IPC 伺服器的呼叫佇列實作。在本節的其餘部分,將省略此前綴。
| 設定金鑰 | 適用的元件 | 說明 | 預設值 |
|---|---|---|---|
| backoff.enable | 一般 | 當佇列已滿時,是否啟用用戶端後退。 | false |
| callqueue.impl | 一般 | 要作為呼叫佇列實作使用的類別的完整限定名稱。對於公平呼叫佇列,請使用 org.apache.hadoop.ipc.FairCallQueue。 |
java.util.concurrent.LinkedBlockingQueue (FIFO 佇列) |
| scheduler.impl | 一般 | 要作為排程器實作使用的類別的完整限定名稱。與公平呼叫佇列一起使用 org.apache.hadoop.ipc.DecayRpcScheduler。 |
org.apache.hadoop.ipc.DefaultRpcScheduler (無操作排程器) 如果使用 FairCallQueue,預設為 org.apache.hadoop.ipc.DecayRpcScheduler |
| scheduler.priority.levels | RpcScheduler、CallQueue | 在排程器和呼叫佇列中要使用的優先順序等級數目。 | 4 |
| faircallqueue.multiplexer.weights | WeightedRoundRobinMultiplexer | 要給予每個優先順序佇列的權重。這應該是一個逗號分隔的清單,長度等於優先順序等級數目。 | 權重以 2 的倍數遞減 (例如,對於 4 個等級:8,4,2,1) |
| identity-provider.impl | DecayRpcScheduler | 將使用者要求對應到其身分的識別提供者。 | org.apache.hadoop.ipc.UserIdentityProvider |
| cost-provider.impl | DecayRpcScheduler | 將使用者要求對應到其成本的成本提供者。若要根據處理時間確定成本,請使用 org.apache.hadoop.ipc.WeightedTimeCostProvider。 |
org.apache.hadoop.ipc.DefaultCostProvider |
| decay-scheduler.period-ms | DecayRpcScheduler | 應將衰減因子套用於使用者操作次數的頻率。較高的值具有較低的開銷,但對用戶端行為變更的反應較慢。 | 5000 |
| decay-scheduler.decay-factor | DecayRpcScheduler | 在衰減使用者的操作計數時,要套用的乘法衰減因子。較高的值會更重視較舊的操作,基本上會讓排程器擁有較長的記憶體,並在較長的時間內懲罰大量的用戶端。 | 0.5 |
| decay-scheduler.thresholds | DecayRpcScheduler | 每個優先佇列的用戶端負載閾值,以整數百分比表示。產生較少負載的用戶端,其總操作數的百分比低於位置 i 所指定的,將會獲得優先順序 i。這應該是一個逗號分隔的清單,其長度等於優先順序等級數減 1(最後一個隱含為 100)。 | 閾值以 2 的倍數遞增(例如,對於 4 個等級:13,25,50) |
| decay-scheduler.backoff.responsetime.enable | DecayRpcScheduler | 是否啟用依據回應時間進行遞延的功能。 | false |
| decay-scheduler.backoff.responsetime.thresholds | DecayRpcScheduler | 每個優先佇列的回應時間閾值,以時間持續時間表示。如果佇列的平均回應時間高於此閾值,遞延將會發生在較低優先順序的佇列中。這應該是一個逗號分隔的清單,其長度等於優先順序等級數。 | 閾值每個等級增加 10 秒(例如,對於 4 個等級:10s,20s,30s,40s) |
| decay-scheduler.metrics.top.user.count | DecayRpcScheduler | 要發出度量資訊的頂尖(即負載最重的)使用者數量。 | 10 |
| weighted-cost.lockshared | WeightedTimeCostProvider | 要套用於處理階段中持有共用(讀取)鎖定的時間的加權乘數。 | 10 |
| weighted-cost.lockexclusive | WeightedTimeCostProvider | 要套用於處理階段中持有獨占(寫入)鎖定的時間的加權乘數。 | 100 |
| weighted-cost.{handler,lockfree,response} | WeightedTimeCostProvider | 要套用於處理階段中不涉及持有鎖定的時間的加權乘數。請參閱 org.apache.hadoop.ipc.ProcessingDetails.Timing 以取得每個階段的更多詳細資訊。 |
1 |
這是使用 FairCallQueue 搭配 DecayRpcScheduler 且只有 2 個優先順序等級,在埠 8020 上組態 IPC 伺服器的範例。負載最重的 10% 使用者會受到嚴厲懲罰,只會獲得 1% 的總處理請求。
<property>
<name>ipc.8020.callqueue.impl</name>
<value>org.apache.hadoop.ipc.FairCallQueue</value>
</property>
<property>
<name>ipc.8020.scheduler.impl</name>
<value>org.apache.hadoop.ipc.DecayRpcScheduler</value>
</property>
<property>
<name>ipc.8020.scheduler.priority.levels</name>
<value>2</value>
</property>
<property>
<name>ipc.8020.faircallqueue.multiplexer.weights</name>
<value>99,1</value>
</property>
<property>
<name>ipc.8020.decay-scheduler.thresholds</name>
<value>90</value>
</property>