
HDFS 中的集中式快取管理是一種明確的快取機制,允許使用者指定要由 HDFS 快取的路徑。NameNode 會與擁有所需區塊的 DataNode 通訊,並指示它們將區塊快取到非堆疊快取中。
HDFS 中的集中式快取管理具有許多顯著的優點。
明確固定可防止頻繁使用的資料從記憶體中移除。這在工作集大小超過主記憶體大小時特別重要,這在許多 HDFS 工作負載中很常見。
由於 DataNode 快取由 NameNode 管理,因此應用程式可以在做出工作配置決策時查詢快取區塊位置的集合。將工作與快取區塊複本放在一起可改善讀取效能。
當區塊已由 DataNode 快取時,客戶端可以使用新的、更有效率的零複製讀取 API。由於快取資料的檢查和驗證是由 DataNode 執行一次,因此客戶端在使用這個新的 API 時基本上不會產生任何負擔。
集中快取可以改善整體叢集記憶體使用率。當依賴每個 DataNode 上的 OS 緩衝快取時,重複讀取區塊會導致區塊的所有 n 個複本都被拉進緩衝快取。透過集中快取管理,使用者可以明確固定 n 個複本中的 m 個,節省 n-m 個記憶體。
HDFS 支援 Linux 平台上的非揮發性儲存類別記憶體 (SCM,也稱為持續性記憶體) 快取。使用者可以為 DataNode 啟用記憶體快取或 SCM 快取。記憶體快取和 SCM 快取可以在 DataNode 中共存。在目前的實作中,當 DataNode 重新啟動時,SCM 中的快取資料會被清除。未來將考慮在 SCM 上提供持續性 HDFS 快取支援。
集中快取管理適用於重複存取的檔案。例如,Hive 中經常用於聯結的小型 事實資料表 非常適合快取。另一方面,快取 一年報表查詢 的輸入可能較不實用,因為歷史資料可能只讀取一次。
集中快取管理也適用於具有效能 SLA 的混合工作負載。快取高優先順序工作負載的工作集可確保它不會與低優先順序工作負載競爭磁碟 I/O。
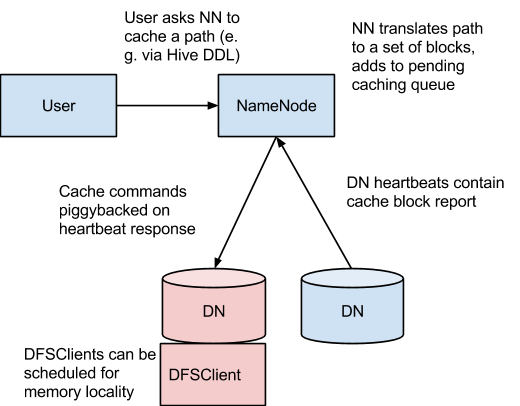
在此架構中,NameNode 負責協調叢集中所有 DataNode 的非堆疊快取。NameNode 會定期從每個 DataNode 收到 快取報告,其中說明快取在特定 DN 上的所有區塊。NameNode 透過在 DataNode 心跳上附加快取和取消快取命令來管理 DataNode 快取。
NameNode 會查詢其 快取指令 集合,以確定應快取哪些路徑。快取指令會持續儲存在 fsimage 和編輯記錄中,而且可以透過 Java 和命令列 API 新增、移除和修改。NameNode 也會儲存一組 快取池,這些是管理實體,用於將快取指令分組在一起以進行資源管理和強制執行權限。
NameNode 會定期重新掃描名稱空間和快取指令,以確定哪些區塊需要快取或取消快取,並將快取工作分配給 DataNode。重新掃描也可以由使用者動作觸發,例如新增或移除快取指令或移除快取池。
我們目前不會快取正在建置、毀損或其他未完成的區塊。如果快取指令涵蓋符號連結,符號連結目標不會被快取。
快取目前在檔案或目錄層級上執行。區塊和子區塊快取是未來的工作項目。
快取指令定義應快取的路徑。路徑可以是目錄或檔案。目錄會以非遞迴方式快取,表示只會快取目錄第一層清單中的檔案。
指令也會指定其他參數,例如快取複製因子和過期時間。複製因子會指定要快取的區塊複製品數量。如果多個快取指令參照同一個檔案,會套用最大的快取複製因子。
過期時間會在命令列上指定為存活時間 (TTL),這是未來相對的過期時間。快取指令過期後,NameNode 在做出快取決策時不再考慮它。
快取池是一種管理快取指令群組的管理實體。快取池具有類 UNIX 的權限,用來限制哪些使用者和群組可以存取池。寫入權限允許使用者新增和移除快取指令至池。讀取權限允許使用者列出池中的快取指令,以及其他元資料。執行權限未用。
快取池也用於資源管理。池可以強制執行最大限制,限制池中指令總共可以快取的位元組數量。通常,池限制的總和大約等於叢集上保留給 HDFS 快取的總記憶體量。快取池也會追蹤一些統計資料,協助叢集使用者判斷什麼是應該快取的內容。
池也可以強制執行最長存活時間。這會限制新增至池的指令的最大過期時間。
cacheadmin 命令列介面在命令列上,管理員和使用者可以透過 hdfs cacheadmin 子指令與快取池和指令互動。
快取指令會以唯一的、不重複的 64 位元整數 ID 來辨識。即使快取指令稍後被移除,ID 也不會重複使用。
快取池會以唯一的字串名稱來辨識。
用法:hdfs cacheadmin -addDirective -path <path> -pool <pool-name> [-force] [-replication <replication>] [-ttl <time-to-live>]
新增快取指令。
| <path> | 要快取的路徑。路徑可以是目錄或檔案。 |
| <pool-name> | 要將指令新增至的池。您必須擁有快取池的寫入權限才能新增指令。 |
| -force | 略過快取池資源限制的檢查。 |
| <replication> | 要使用的快取複製因子。預設為 1。 |
| <time-to-live> | 指令有效的時間長度。可以以分鐘、小時和天數指定,例如 30m、4h、2d。有效的單位為 [smhd]。「never」表示永不過期的指令。如果未指定,指令永不過期。 |
用法:hdfs cacheadmin -removeDirective <id>
移除快取指令。
| <id> | 要移除的快取指令 ID。您必須擁有指令池的寫入權限才能移除指令。若要查看快取指令 ID 清單,請使用 -listDirectives 指令。 |
用法:hdfs cacheadmin -removeDirectives <path>
移除具有指定路徑的所有快取指令。
| <path> | 要移除的快取指令路徑。您必須擁有指令池的寫入權限才能移除指令。若要查看快取指令清單,請使用 -listDirectives 指令。 |
用法:hdfs cacheadmin -listDirectives [-stats] [-path <path>] [-pool <pool>]
列出快取指令。
| <path> | 僅列出具有此路徑的快取指令。請注意,如果我們沒有讀取權限,則不會列出快取池中 path 的快取指令。 |
| <pool> | 僅列出該池中的路徑快取指令。 |
| -stats | 列出基於路徑的快取指令統計資料。 |
用法:hdfs cacheadmin -addPool <name> [-owner <owner>] [-group <group>] [-mode <mode>] [-limit <limit>] [-maxTtl <maxTtl>]
新增快取池。
| <name> | 新池的名稱。 |
| <擁有者> | 池擁有者的使用者名稱。預設為目前使用者。 |
| <群組> | 池的群組。預設為目前使用者的主要群組名稱。 |
| <模式> | 池的 UNIX 風格權限。權限以八進位制指定,例如 0755。預設為 0755。 |
| <限制> | 此池中指令快取的位元組數上限。預設不設限。 |
| <maxTtl> | 新增至池中指令允許的最大存活時間。可指定為秒、分、時和日,例如 120s、30m、4h、2d。有效的單位為 [smhd]。預設不設上限。值為 "never " 表示沒有限制。 |
用法:hdfs cacheadmin -modifyPool <name> [-owner <owner>] [-group <group>] [-mode <mode>] [-limit <limit>] [-maxTtl <maxTtl>]
修改現有快取池的元資料。
| <name> | 要修改的池名稱。 |
| <擁有者> | 池擁有者的使用者名稱。 |
| <群組> | 池群組的群組名稱。 |
| <模式> | 池的八進位制 Unix 風格權限。 |
| <限制> | 此池可快取的位元組數上限。 |
| <maxTtl> | 新增至池中指令允許的最大存活時間。 |
用法:hdfs cacheadmin -removePool <name>
移除快取池。這也會取消與池相關聯路徑的快取。
| <name> | 要移除的快取池名稱。 |
用法:hdfs cacheadmin -listPools [-stats] [<name>]
顯示一個或多個快取池的資訊,例如名稱、擁有者、群組、權限等。
| -stats | 顯示其他快取池統計資料。 |
| <name> | 如果指定,只列出指定名稱的快取池。 |
用法:hdfs cacheadmin -help <command-name>
取得指令的詳細說明。
| <command-name> | 要取得詳細說明的指令。如果未指定指令,則印出所有指令的詳細說明。 |
為了將區塊檔案鎖定在記憶體中,DataNode 依賴於 libhadoop.so 或 Windows 上的 hadoop.dll 中的原生 JNI 程式碼。如果您使用 HDFS 集中化快取管理,請務必 啟用 JNI。
目前,持續性記憶體快取有兩種實作方式。預設為純 Java 基礎實作,另一種為原生實作,它利用 PMDK 函式庫來提升快取寫入和快取讀取的效能。
若要啟用基於 PMDK 的實作,請執行下列步驟。
安裝 PMDK 函式庫。有關詳細資訊,請參閱官方網站 http://pmem.io/。
使用 PMDK 支援來建置 Hadoop。請參閱原始碼中 BUILDING.txt 的「PMDK 函式庫建置選項」區段。
若要驗證 Hadoop 是否正確偵測到 PMDK,請執行 hadoop checknative 指令。
務必為 DRAM 快取或持續性記憶體快取組態下列其中一個屬性。請注意,DRAM 快取和持續性快取無法同時存在於資料節點上。
dfs.datanode.max.locked.memory
這會決定資料節點將用於快取的最大記憶體量。在類 Unix 系統上,資料節點使用者的「鎖定記憶體大小」ulimit (ulimit -l) 也需要增加以符合此參數 (請參閱下方有關 作業系統限制 的區段)。設定此值時,請記住您也需要在記憶體中為其他項目保留空間,例如資料節點和應用程式 JVM 堆積和作業系統分頁快取。
此設定與 延遲寫入持久化功能 共用。資料節點將確保延遲寫入持久化和集中式快取管理所使用的記憶體總和不會超過 dfs.datanode.max.locked.memory 中組態的量。
dfs.datanode.pmem.cache.dirs
此屬性指定持續性記憶體的快取磁碟區。對於多個磁碟區,應以「,」分隔,例如「/mnt/pmem0, /mnt/pmem1」。預設值為空。如果組態此屬性,將會偵測磁碟區容量。而且不需要組態 dfs.datanode.max.locked.memory。
下列屬性不是必要的,但可以指定用於調整
dfs.namenode.path.based.cache.refresh.interval.ms
NameNode 會將此值用作後續路徑快取重新掃描之間的毫秒數。這會計算要快取的區塊,以及包含該區塊複本的每個資料節點都應該快取該區塊。
預設情況下,此參數設定為 30000,也就是三十秒。
dfs.datanode.fsdatasetcache.max.threads.per.volume
資料節點會將此值用作每一個磁碟區用於快取新資料的最大執行緒數。
預設情況下,此參數設定為 4。
dfs.cachereport.intervalMsec
DataNode 會將此值視為傳送快取狀態完整報告給 NameNode 之間的毫秒數。
預設情況下,此參數設定為 10000,即 10 秒。
dfs.namenode.path.based.cache.block.map.allocation.percent
我們會將 Java 堆積的百分比分配給快取區塊映射。快取區塊映射是一個雜湊映射,使用鏈結雜湊。如果快取區塊數量龐大,較小的映射存取速度可能會較慢;較大的映射會消耗更多記憶體。預設值為 0.25%。
dfs.namenode.caching.enabled
此參數可用於啟用/停用 NameNode 中的集中式快取。當集中式快取停用時,NameNode 就不會處理快取報告或儲存叢集上區塊快取位置的資訊。請注意,即使 NameNode 暫時不會根據此資訊採取行動,它仍會繼續將基於路徑的快取位置儲存在檔案系統的元資料中,直到快取功能啟用為止。此參數的預設值為 true (即啟用集中式快取)。
dfs.datanode.pmem.cache.recovery
此參數用於確定是否在 DataNode 啟動期間復原持續性記憶體上先前快取的狀態。如果啟用,DataNode 會復原持續性記憶體上先前快取資料的狀態。因此,可以避免重新快取資料。如果未啟用此屬性,DataNode 會清除持續性記憶體上先前快取 (如果有)。此屬性僅在啟用持續性記憶體時才能運作,即已設定 dfs.datanode.pmem.cache.dirs。
如果您收到錯誤訊息「無法啟動資料節點,因為設定的最大鎖定記憶體大小…大於資料節點可用的 RLIMIT_MEMLOCK ulimit」,這表示作業系統對您可以鎖定的記憶體量施加的限制低於您設定的限制。若要修復此問題,您必須調整 DataNode 執行的 ulimit -l 值。通常,此值會在 /etc/security/limits.conf 中設定。但是,它會根據您使用的作業系統和發行版而異。
當您從 shell 執行 ulimit -l 並取得比您使用 dfs.datanode.max.locked.memory 設定的更高值,或取得表示沒有限制的字串「unlimited」時,表示您已正確設定此值。請注意,ulimit -l 通常會以 KB 為單位輸出記憶體鎖定限制,但 dfs.datanode.max.locked.memory 必須以位元組為單位指定。
此資訊不適用於 Windows 上的部署。Windows 沒有 ulimit -l 的直接等效項。